von über 52472 zufriedenen Nutzern
Z-Image Turbo
Kostenloser Z-Image Turbo AI Image Generator Online, das 6B Z Image AI-Modell von Tongyi-MAI. Erstellen und bearbeiten Sie Bilder mit Z Image Turbo und Z-Image-Edit.
Z-Image Turbo AI-Bildgenerator
Erstellen und bearbeiten Sie Bilder mit Textansagen oder Bildern mit Z-Image Turbo AI

Z-Image-Inspirationsgalerie
Entdecken Sie, was mit den Z-Image Turbo-Generierungsfunktionen möglich ist. Klicken Sie auf ein beliebiges Element, um Z-Image-Eingabeaufforderungen anzuzeigen.






![[Art Style & Viewpoint]:
Hyper-realistic 8k product photography, macro lens perspective, strict 90-degree overhead flat-lay (knolling).
[Aesthetic Philosophy]: "Sublime Micro-Engineering Narratives". A blend of surgical precision and artistic interpretation of technical components.
[Subject Input]:
Target Object: Deconstructed Leica M3 Camera Body
[Action]: Forensic Technical Exploded View. Disassemble into 8-12 primary components, but with an emphasis on secondary and tertiary sub-components (e.g., individual gears within a gearbox, micro-switches on a circuit board, specific spring types, internal wiring harnesses).
[Detail Emphasis]: Each component is meticulously rendered.
Metals: Highlight brushed grains, polished edges, anodic oxidation sheen, laser-etched serial numbers or specific alloy markings. Show microscopic tolerances between parts.
Plastics: Reveal injection molding marks, precise seam lines, and subtle textural variations.
Circuitry: Emphasize the solder joints, traces, tiny capacitors, and integrated chip details.
Glass/Optics: Render reflections, anti-reflective coatings, and subtle refractions.
[Background]: Premium matte cool-grey workbench surface.
[Interactive Schematics]: Ultra-fine Cyan/Tech-Blue vector lines. Include cross-sectional views, exploded assembly sequence lines (dashed arrows), and material call-outs (e.g., "Alloy 7075", "Carbon Fiber Weave").
[Artistic Title Style]: "Industrial Stencil" Aesthetic. Large, bold, semi-transparent text (e.g., "PROJECT: ALPHA" or "ENGINE MODEL: X9") laser-etched onto the background surface.](https://pub-eb5b81bfee5c4e39ba2d1f7195360ef2.r2.dev/inspiration/7.jpeg)













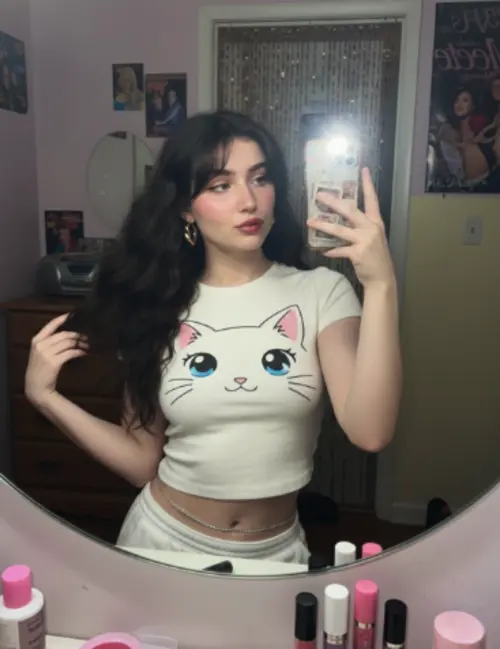




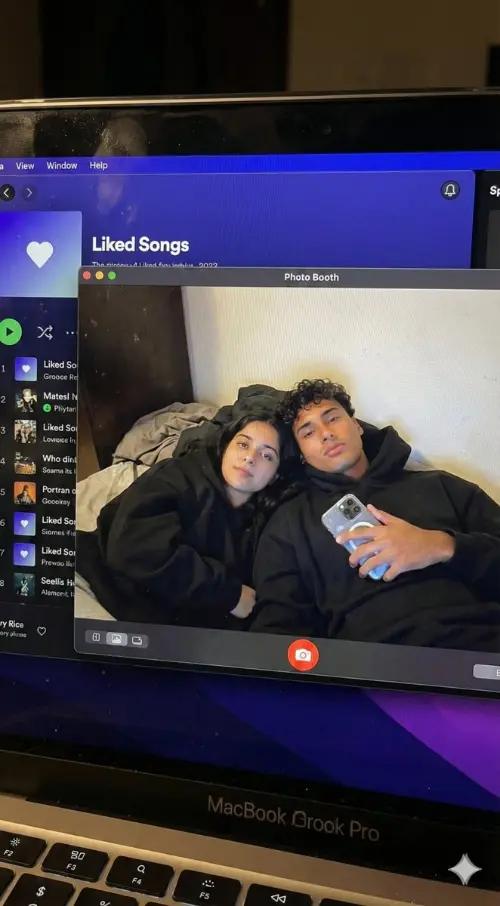
Vergleich verschiedener Modellergebnisse
Sehen Sie, wie verschiedene KI-Modelle mit derselben Eingabeaufforderung unterschiedliche Ergebnisse erzeugen.
Originalbild

Erstellen Sie bei Comiket ein sehr detailliertes Foto eines Mädchens, das diese Illustration verkörpert. Reproduzieren Sie genau die gleiche Pose, Körperhaltung, Handgesten, Mimik und Kameraeinstellung wie in der Originalillustration. Behalten Sie den gleichen Blickwinkel, die gleiche Perspektive und die gleiche Komposition bei, ohne Abweichungen
Generierte Ergebnisse

Flux Pro

Qwen

Seedream

Nano Banana













Modelle

Nano Banana 2
NeuNeueste Generation mit verbesserter Qualität
Nano Banana
HervorgehobenExtrem hohe Charakterkonsistenz

Seedream
NeuUnterstützt Bilder mit kohärenten Stilen

Flux Dev
Für kurze und einfache Szenen

Qwen
NeuGut bei komplexer Textwiedergabe
Flux Schnell Lora
NeuSchnelle, kreative Bildgenerierung
Flux Kontext
Für Fotorealismus und kreative Kontrolle
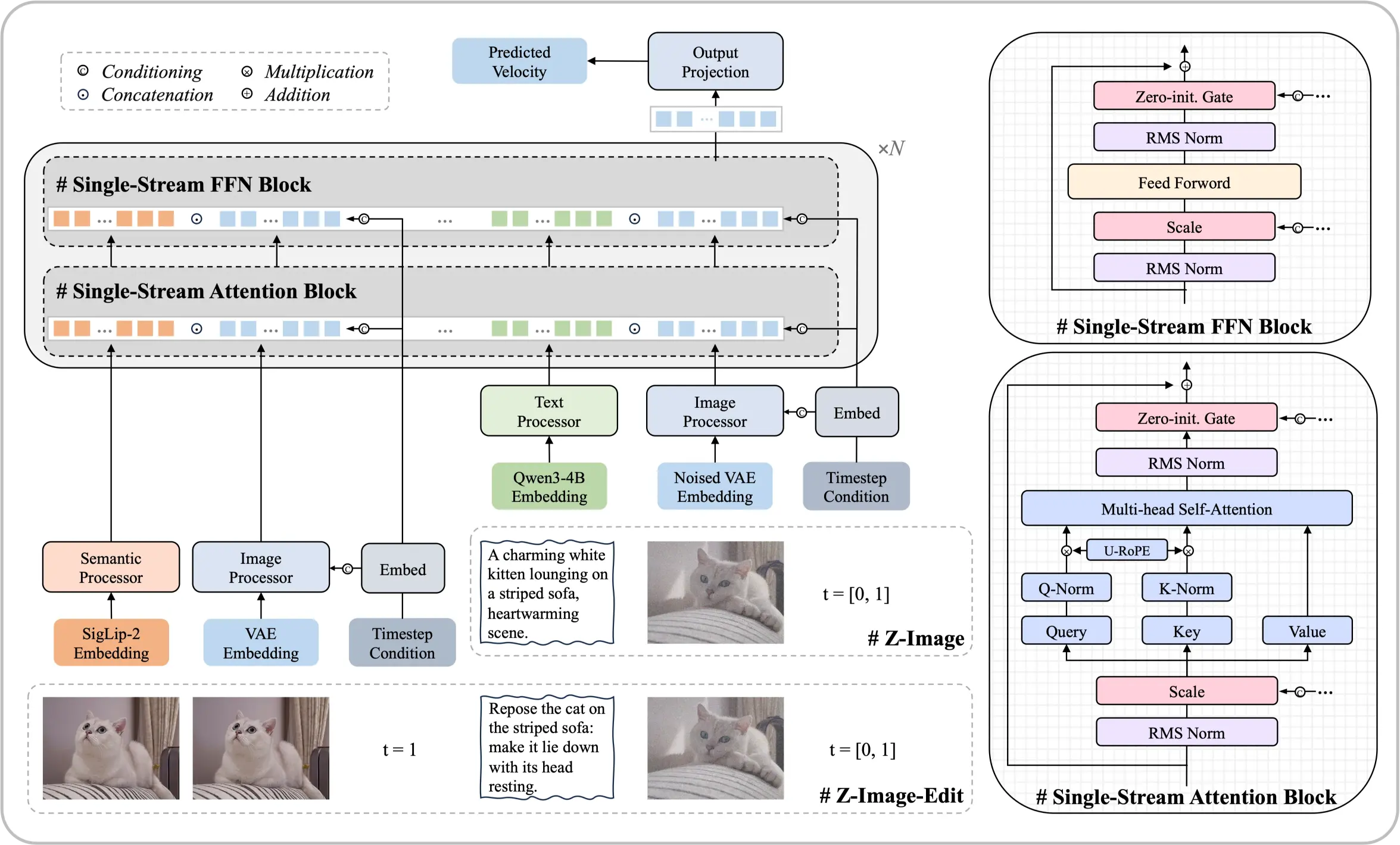
Lernen Sie das Z-Image Foundation-Modell kennen
Eine Architektur mit 6 Milliarden Parametern, die beweist, dass Spitzenergebnisse ohne massive Rechenressourcen erreichbar sind. Dieses Open-Source-Diffusionsmodell liefert fotorealistische Ausgaben und zweisprachiges Textrendering vergleichbar mit führenden kommerziellen Lösungen.
- Single-Stream-ArchitekturVereint Texteinbettungen und latente Verarbeitung in einer effizienten Transformatorsequenz.
- Fotografischer RealismusPräzise Kontrolle über Beleuchtung, Texturen und Details, die professionellen Standards entsprechen.
- Chinesischer & Englischer TextPräzise Wiedergabe von zweisprachigem Text direkt in generierten Bildern.
Kernstärken dieses Modells
Systematische Optimierung ermöglicht Leistung, die mit einer Größenordnung größeren Modellen konkurriert.
Erste Schritte mit Z-Image
Erstellen Sie beeindruckende Bilder in vier einfachen Schritten:
Was Z-Image auszeichnet
Entdecken Sie die Funktionen, die Z-Image zu einem Spitzenreiter unter den Open-Source-Alternativen machen.
ComfyUI-Integration
Z-Image-Knoten bieten native Workflow-Unterstützung für den nahtlosen Pipeline-Aufbau.
Professionelle Typografie
Starke Kompositionsfähigkeiten für Posterdesign mit präziser Textplatzierung.
Mehrstufige Anweisungen
Befolgt komplexe zusammengesetzte Prompts mit logischer Kohärenz.
Ästhetisches Gleichgewicht
High-Fidelity-Bilder mit ansprechender Komposition und Stimmung.
Huggingface & ModelScope
Modellgewichte zum Download auf großen Modell-Repositories verfügbar.
GGUF & FP8-Formate
Optimierte quantisierte Versionen für effizienten lokalen Einsatz.
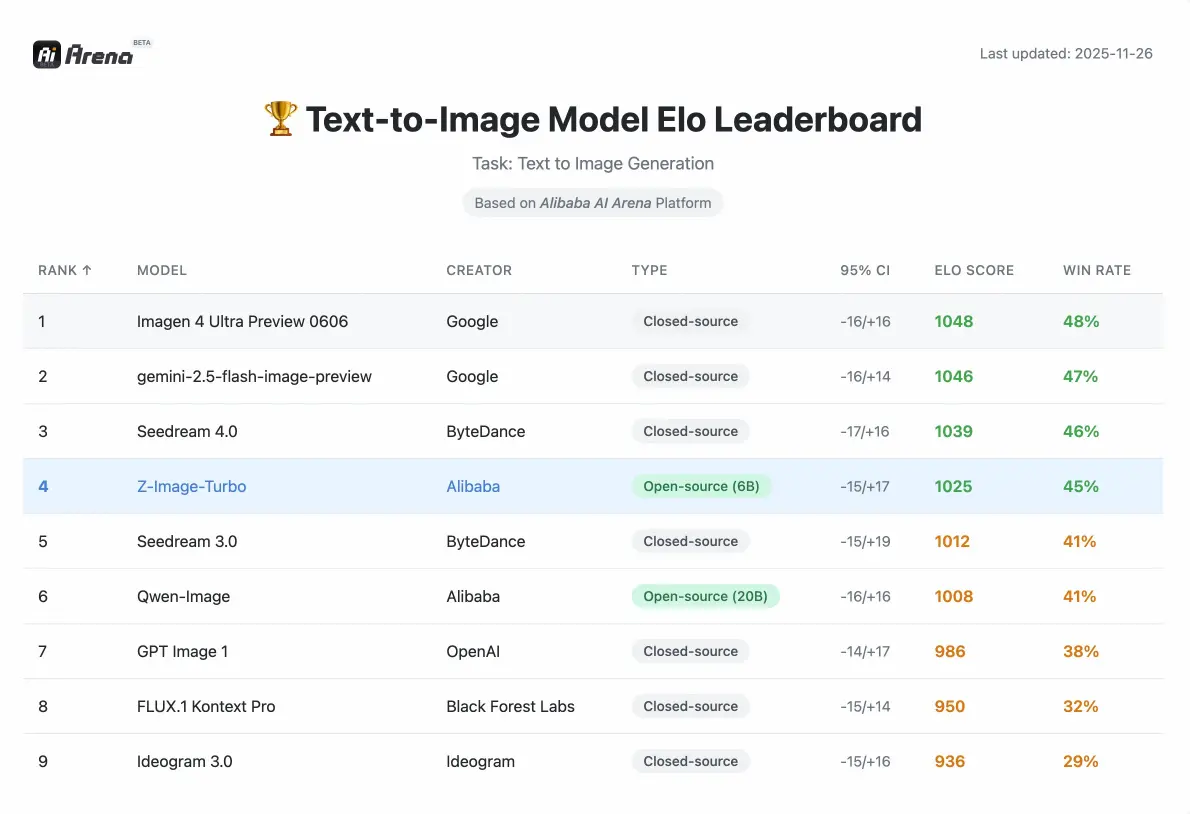
Z-Image-Leistung
Wettbewerbsfähige Kennzahlen, validiert durch menschliche Präferenzbewertungen in der Alibaba AI Arena.
Parameter
6B
Kompakt und dennoch leistungsstark
Schritte (Turbo)
8
Schnelle Generierung
VRAM erforderlich
<16GB
Consumer-Hardware
Was Entwickler über Z-Image sagen
Erfahrungen von Designern, Entwicklern und Content-Erstellern, die unsere Tools verwenden.
David
Grafikdesigner
Die fotorealistische Qualität kann mit teuren kommerziellen Werkzeugen mithalten. Ich habe es innerhalb weniger Minuten in meine ComfyUI-Pipeline integriert.
Rachel
Content-Erstellerin
Das zweisprachige Textrendering ist ein Game-Changer. Chinesische Zeichen kommen gestochen scharf heraus, ohne jegliche Nachbearbeitung.
Marcus
Entwickler
Habe die GGUF-Version von Huggingface heruntergeladen und sie lief am selben Nachmittag lokal. Sehr unkompliziert.
Sofia
Marketingdirektorin
Die Edit-Variante folgt komplexen Anweisungen präzise. Wir nutzen es für schnelle Produktfotoanpassungen.
James
E-Commerce
Das Verständnis für Szenenkompositionen ist exzellent. Produkthintergründe sehen professionell fotografiert aus.
Anna
Künstlerin
Die kulturelle Genauigkeit hat mich beeindruckt. Es generiert spezifische Wahrzeichen und traditionelle Elemente ohne Halluzinationen.
Häufig gestellte Fragen zu Z-Image
Alles, was Sie über Z-Image, die ComfyUI-Integration und das Herunterladen von Huggingface wissen müssen.
Was genau ist Z-Image?
Z-Image ist ein effizientes 6-Milliarden-Parameter-Grundmodell zur Generierung von Bildern. Es basiert auf einer Single-Stream-Diffusion-Transformer-Architektur und liefert fotorealistische Qualität und zweisprachige Textwiedergabe, die mit führenden kommerziellen Lösungen vergleichbar ist – ohne große Rechenressourcen zu erfordern.
Wie funktioniert die Single-Stream-Diffusionsarchitektur?
Diese Architektur vereinheitlicht die Verarbeitung von Texteinbettungen, bedingten Eingaben und verrauschten Latenten in einer einzigen Sequenz, die in den Transformer-Backbone eingespeist wird. Dieser optimierte Ansatz verbessert die Effizienz bei gleichzeitiger Beibehaltung einer hohen Ausgabequalität, sodass das Modell auf Hardware der Verbraucherklasse ausgeführt werden kann.
Was ist Z-Image-Turbo?
Z-Image-Turbo ist eine destillierte, auf Geschwindigkeit optimierte Variante. Es erreicht eine fotorealistische Generierung mit präziser zweisprachiger Textwiedergabe in nur 8 Inferenzschritten und liefert Ergebnisse, die mit denen der Konkurrenz vergleichbar sind oder diese übertreffen, die viel mehr Schritte erfordern.
Was ist Z-Image-Edit?
Z-Image-Edit ist eine Weiterbildungsvariante, die auf die Bearbeitung vorhandener Bilder spezialisiert ist. Es zeichnet sich durch die Befolgung komplexer Anweisungen für Aufgaben aus, die von präzisen lokalen Anpassungen bis hin zu globalen Stiltransformationen reichen, und behält dabei die Bearbeitungskonsistenz bei.
Kann ich dies mit ComfyUI verwenden?
Ja. Das Modell lässt sich über benutzerdefinierte Knoten nativ in ComfyUI integrieren. Sie können komplexe Workflows erstellen, die Generierung, Bearbeitung und Nachbearbeitung innerhalb der ComfyUI-Oberfläche kombinieren. Für einen schnellen Einstieg stehen von der Community erstellte Workflow-Vorlagen zur Verfügung.
Wo kann ich die Modellgewichte herunterladen?
Modellgewichte sind sowohl für Huggingface als auch für ModelScope verfügbar. Je nach Anwendungsfall können Sie das Basismodell, die Turbo-Variante oder die Edit-Variante herunterladen. Für eine effiziente lokale Bereitstellung werden auch quantisierte GGUF- und FP8-Versionen bereitgestellt.
Welche Hardware benötige ich, um es lokal auszuführen?
Das Modell läuft reibungslos auf Consumer-Grafikkarten mit weniger als 16GB VRAM. Dies macht fortschrittliche Generierungstechnologie zugänglich, ohne teure professionelle Hardware zu benötigen. Die quantisierten GGUF- und FP8-Versionen reduzieren die Speicheranforderungen weiter.
Unterstützt es chinesischen Text in generierten Bildern?
Ja. Das Modell verfügt über hervorragende zweisprachige Wiedergabefunktionen für chinesischen und englischen Text. Es kann Text präzise in Bildern platzieren und dabei die ästhetische Komposition und Lesbarkeit beibehalten, selbst bei kleineren Schriftgrößen.
Wie schneidet die Leistung im Vergleich zu anderen Open-Source-Modellen ab?
Laut der Elo-basierten Human Preference Evaluation auf der Alibaba AI Arena zeigt dieses Modell eine äußerst wettbewerbsfähige Leistung gegenüber führenden Alternativen und erzielt in seiner Parameterklasse modernste Ergebnisse unter Open-Source-Optionen.
Was ist der Prompt Enhancer?
Der Prompt Enhancer (PE) verwendet eine strukturierte Argumentationskette, um Logik und gesunden Menschenverstand in den Generierungsprozess einzubringen. Dies ermöglicht die Bewältigung komplexer Aufgaben wie das Huhn-und-Kaninchen-Problem oder die Visualisierung klassischer Poesie mit logischer Kohärenz.
Ist das Modell wirklich Open Source?
Ja. Der Code, die Gewichte und eine Online-Demo sind öffentlich verfügbar. Ziel ist es, die Entwicklung zugänglicher, kostengünstiger und leistungsstarker generativer Modelle zu fördern, die der gesamten Forschungs- und Entwicklergemeinschaft zugute kommen.
Kann es komplexe mehrteilige Anweisungen verarbeiten?
Hier punktet vor allem die Edit-Variante. Es kann zusammengesetzte Anweisungen ausführen, z. B. gleichzeitig den Ausdruck und die Pose einer Figur ändern und gleichzeitig spezifischen Text hinzufügen, wodurch die Konsistenz aller Änderungen gewahrt bleibt.
Wie ist das kulturelle Verständnis implementiert?
Das Modell verfügt über umfangreiches Wissen über Weltdenkmäler, historische Persönlichkeiten, kulturelle Konzepte und spezifische reale Objekte. Dies ermöglicht präzise Generierung verschiedener Themen ohne Halluzinationen oder kulturelle Ungenauigkeiten.
Was macht die Textwiedergabe besonders?
Über die zweisprachige Unterstützung hinaus zeigt das Modell starke typografische Fähigkeiten für Posterdesign und komplexe Kompositionen. Es bewältigt anspruchsvolle Szenarien wie kleine Schriftgrößen oder komplizierte Layouts und bewahrt dabei textliche Präzision und visuelle Attraktivität.
Wie integriere ich es in meine bestehende Pipeline?
Für ComfyUI-Nutzer laden Sie einfach die benutzerdefinierten Nodes herunter und laden die Modellgewichte. Für programmatischen Zugriff folgt das Modell Standard-Diffusionsmodell-APIs. Die Dokumentation enthält Beispielcode für Python-Integration, API-Endpunkte und Workflow-Vorlagen.
Was ist mit den FP8- und GGUF-Versionen?
Dies sind quantisierte Versionen, die für effizienten Einsatz optimiert sind. FP8 behält hohe Qualität mit reduzierter Präzision bei, während GGUF maximale Kompatibilität für lokale Inferenz bietet. Beide reduzieren die VRAM-Anforderungen gegenüber dem Basismodell.
Kann ich es für kommerzielle Projekte verwenden?
Das Modell wird als Open Source mit einer permissiven Lizenz veröffentlicht. Überprüfen Sie die spezifischen Lizenzdetails auf der Repository-Seite für kommerzielle Nutzungsrichtlinien. Die meisten Standard-Geschäftsanwendungen sind erlaubt.
Wie schneidet es im Vergleich zu Stable Diffusion ab?
Obwohl beide diffusionsbasiert sind, verwendet dieses Modell eine eigene Single-Stream-Architektur, die die Verarbeitung vereinheitlicht. Es zeichnet sich besonders durch die zweisprachige Textwiedergabe und das Befolgen von Anweisungen aus, Bereiche, in denen Standardmodelle mit stabiler Diffusion häufig Probleme haben.
Welche Auflösung unterstützt es?
Das Basismodell unterstützt Standardauflösungen, die für Qualität und Geschwindigkeit optimiert sind. Höhere Auflösungen sind durch den ComfyUI-Workflow mit entsprechenden Upscaling-Nodes erreichbar. Überprüfen Sie die Dokumentation für empfohlene Auflösungseinstellungen.
Ist eine API verfügbar?
Ja. Es werden sowohl eine Webdemo als auch ein programmgesteuerter API-Zugriff bereitgestellt. Bei Bedarf können Sie Generierungsfunktionen direkt in Ihre Anwendungen integrieren, ohne die lokale Infrastruktur verwalten zu müssen.
Wie oft wird das Modell aktualisiert?
Das Entwicklungsteam pflegt und verbessert das Modell aktiv. Updates umfassen Leistungsoptimierungen, erweiterte Fähigkeiten und von der Community gewünschte Funktionen. Folgen Sie dem Repository für Ankündigungen.
Kann es Gesichter genau generieren?
Das Modell erzeugt äußerst realistische Gesichtszüge mit feiner Kontrolle über Mimik und Details. In Kombination mit präzisen Textüberlagerungsfunktionen eignet es sich besonders für hochformatige Inhalte und Marketingmaterialien.
Wie sieht es mit Stiltransfer und künstlerischen Effekten aus?
Die Edit-Variante übernimmt Stiltransformationen unter Wahrung der Subjektidentität. Sie können künstlerische Effekte anwenden, Hintergründe ändern oder die Ästhetik modifizieren und dabei die Konsistenz der visuellen Kernelemente beibehalten.
Wie funktionieren LoRA-Anpassungen mit diesem Modell?
Benutzerdefinierte LoRA-Gewichte können trainiert und angewendet werden, um das Modell auf bestimmte Stile oder Themen zu spezialisieren. Die Architektur unterstützt Standard-LoRA-Integrationsmethoden, die Nutzern anderer Diffusionsmodelle vertraut sind.
Was macht es im Vergleich zu größeren Modellen effizient?
Durch systematische Optimierung auf Architekturebene können 6B-Parameter mit den Ausgaben zehnmal größerer Modelle übereinstimmen. Diese Effizienz führt zu schnelleren Inferenzen, geringeren Hardwareanforderungen und geringeren Betriebskosten.
Ist Community-Support verfügbar?
Ja. Aktive Communities existieren auf Discord, GitHub und Foren, wo Nutzer Workflows teilen, Probleme beheben und Kreationen präsentieren. Das Entwicklungsteam engagiert sich regelmäßig mit Community-Feedback.
Wie melde ich Fehler oder fordere Funktionen an?
Das GitHub-Repository akzeptiert Issues für Fehlerberichte und Funktionsanfragen. Community-Beteiligung hilft, Verbesserungen zu priorisieren und sicherzustellen, dass sich das Modell weiterentwickelt, um den Nutzerbedürfnissen gerecht zu werden.
Können Anfänger dies ohne technisches Wissen nutzen?
Die Web-Demo bietet eine No-Code-Oberfläche für sofortige Nutzung. Für lokalen Einsatz bietet ComfyUI visuelle Workflow-Erstellung ohne Programmierung. Technische Nutzer können die vollständige API für programmatische Kontrolle nutzen.
Was unterscheidet dies von Qwen-basierten Bildmodellen?
Während sich Qwen auf das Verstehen von Vision und Sprache konzentriert, ist dieses Modell auf die Generierung mit einzigartigen Stärken in der zweisprachigen Textwiedergabe und der anweisungenfolgenden Bearbeitung spezialisiert. Beide können sich in umfassenden KI-Pipelines ergänzen.
Wird Batch-Verarbeitung unterstützt?
Ja. Sowohl die API als auch ComfyUI-Workflows unterstützen Batch-Generierung zur effizienten Verarbeitung mehrerer Prompts. Dies ist nützlich für Produktionsumgebungen, die hohen Durchsatz erfordern.
Beginnen Sie mit der Erstellung mit Z-Image
Erleben Sie effiziente Generierung mit diesem Open-Source-Grundlagenmodell. Kostenlos zu verwenden.