de más de 52472 usuarios felices
Turbo de imagen Z
Generador de imágenes Z-Image Turbo AI gratuito en línea, el modelo de IA de imágenes 6B Z de Tongyi-MAI. Cree y edite imágenes con Z Image Turbo y Z-Image-Edit.
Generador de imágenes Z-Image Turbo AI
Genere y edite imágenes con mensajes de texto o imágenes con Z-Image Turbo AI

Galería de inspiración de Z-Image
Explore lo que es posible con las capacidades de generación Z-Image Turbo. Haga clic en cualquier elemento para ver las indicaciones de Z-Image.






![[Art Style & Viewpoint]:
Hyper-realistic 8k product photography, macro lens perspective, strict 90-degree overhead flat-lay (knolling).
[Aesthetic Philosophy]: "Sublime Micro-Engineering Narratives". A blend of surgical precision and artistic interpretation of technical components.
[Subject Input]:
Target Object: Deconstructed Leica M3 Camera Body
[Action]: Forensic Technical Exploded View. Disassemble into 8-12 primary components, but with an emphasis on secondary and tertiary sub-components (e.g., individual gears within a gearbox, micro-switches on a circuit board, specific spring types, internal wiring harnesses).
[Detail Emphasis]: Each component is meticulously rendered.
Metals: Highlight brushed grains, polished edges, anodic oxidation sheen, laser-etched serial numbers or specific alloy markings. Show microscopic tolerances between parts.
Plastics: Reveal injection molding marks, precise seam lines, and subtle textural variations.
Circuitry: Emphasize the solder joints, traces, tiny capacitors, and integrated chip details.
Glass/Optics: Render reflections, anti-reflective coatings, and subtle refractions.
[Background]: Premium matte cool-grey workbench surface.
[Interactive Schematics]: Ultra-fine Cyan/Tech-Blue vector lines. Include cross-sectional views, exploded assembly sequence lines (dashed arrows), and material call-outs (e.g., "Alloy 7075", "Carbon Fiber Weave").
[Artistic Title Style]: "Industrial Stencil" Aesthetic. Large, bold, semi-transparent text (e.g., "PROJECT: ALPHA" or "ENGINE MODEL: X9") laser-etched onto the background surface.](https://pub-eb5b81bfee5c4e39ba2d1f7195360ef2.r2.dev/inspiration/7.jpeg)













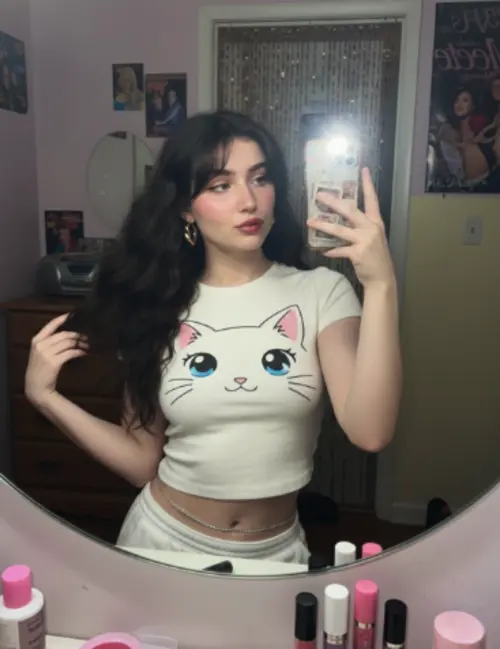




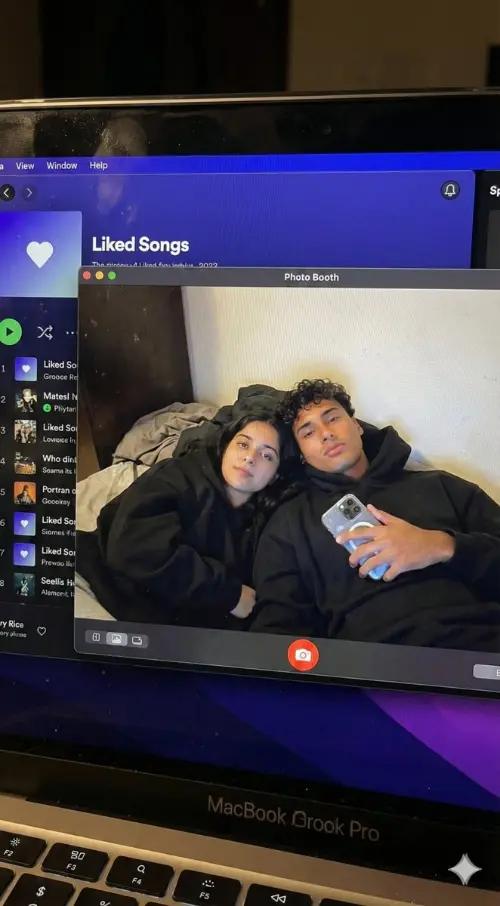
Comparación de resultados de diferentes modelos
Vea cómo diferentes modelos de IA generan resultados variados con el mismo prompt.
Imagen original

Genera una foto muy detallada de una chica haciendo cosplay de esta ilustración, en Comiket. Replica exactamente la misma pose, postura corporal, gestos de manos, expresión facial y encuadre de cámara que en la ilustración original. Mantén el mismo ángulo, perspectiva y composición, sin ninguna desviación.
Resultados generados

Flux Pro

Qwen

Seedream

Nano Banana













Modelos

Nano Banana 2
NuevoÚltima generación con calidad mejorada
Nano Banana
DestacadoConsistencia de personajes ultra-alta

Seedream
NuevoSoporta imágenes con estilos coherentes

Flux Dev
Para escenas cortas y básicas

Qwen
NuevoExperto en renderizado de texto complejo
Flux Schnell Lora
NuevoGeneración de imágenes rápida y creativa
Flux Kontext
Para fotorrealismo y control creativo
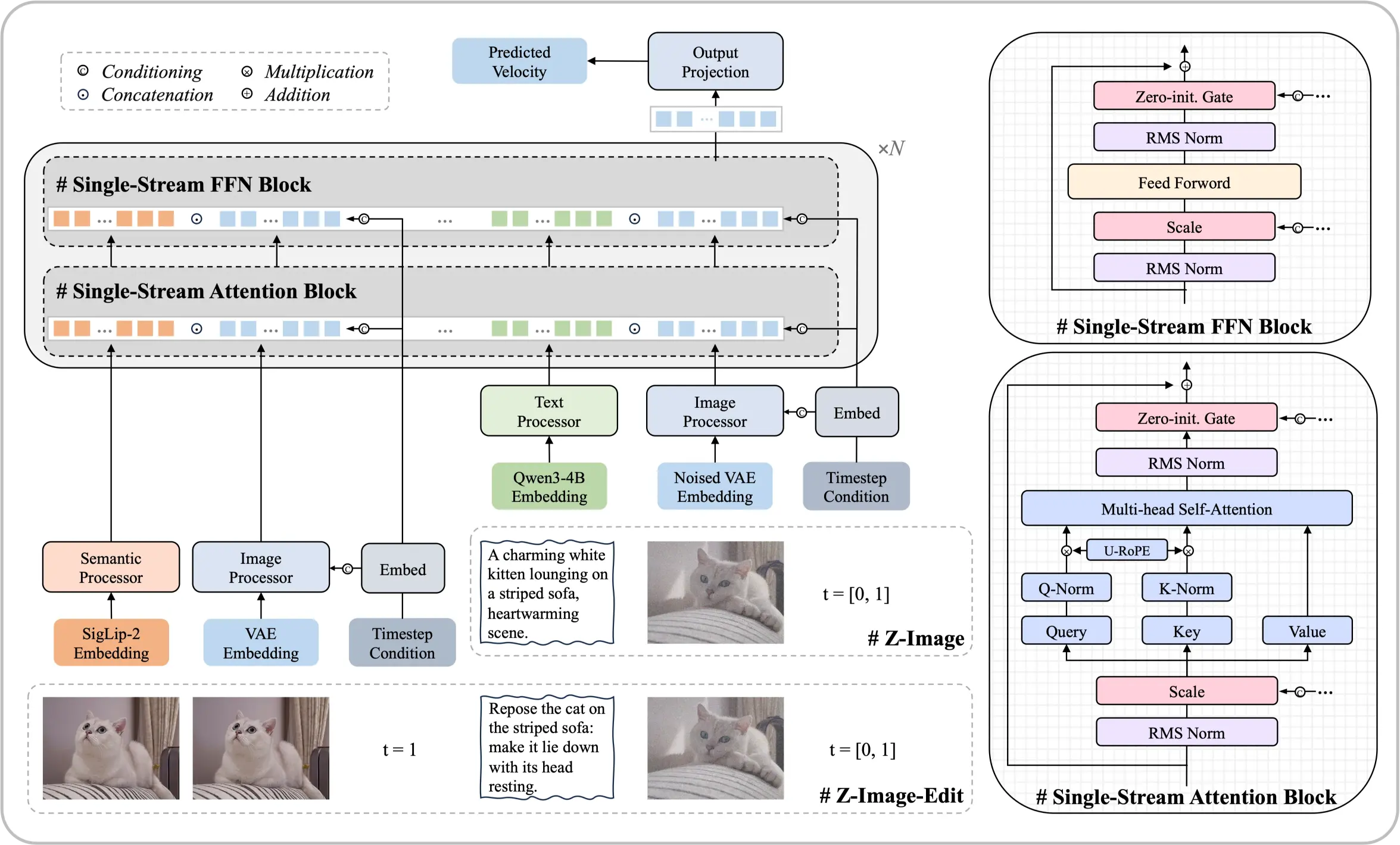
Conozca el modelo Z-Image Foundation
Una arquitectura de 6 mil millones de parámetros que demuestra que se pueden lograr resultados de primer nivel sin recursos computacionales masivos. Este modelo de difusión de código abierto ofrece salidas fotorrealistas y renderizado de texto bilingüe comparable a las principales soluciones comerciales.
- Arquitectura de Flujo ÚnicoUnifica incrustaciones de texto y procesamiento latente en una secuencia de transformer eficiente.
- Realismo FotográficoControl preciso sobre iluminación, texturas y detalles que cumplen estándares profesionales.
- Texto en Chino e InglésRenderizado preciso de texto bilingüe directamente dentro de las imágenes generadas.
Fortalezas Principales de Este Modelo
La optimización sistemática permite un rendimiento que rivaliza con modelos de un orden de magnitud mayor.
Primeros pasos con Z-Imagen
Crea imágenes impresionantes en cuatro simples pasos:
Lo que distingue a Z-Image
Explore las capacidades que hacen de Z-Image un líder entre las alternativas de código abierto.
Integración con ComfyUI
Los nodos Z-Image brindan soporte de flujo de trabajo nativo para la creación de canalizaciones sin problemas.
Tipografía Profesional
Habilidades compositivas avanzadas para diseño de carteles con colocación precisa de texto.
Instrucciones Multipaso
Sigue prompts compuestos complejos con coherencia lógica.
Balance Estético
Imágenes de alta fidelidad con composición y atmósfera agradables.
Huggingface y ModelScope
Pesos disponibles para descarga en los principales repositorios de modelos.
Formatos GGUF y FP8
Versiones cuantizadas optimizadas para implementación local eficiente.
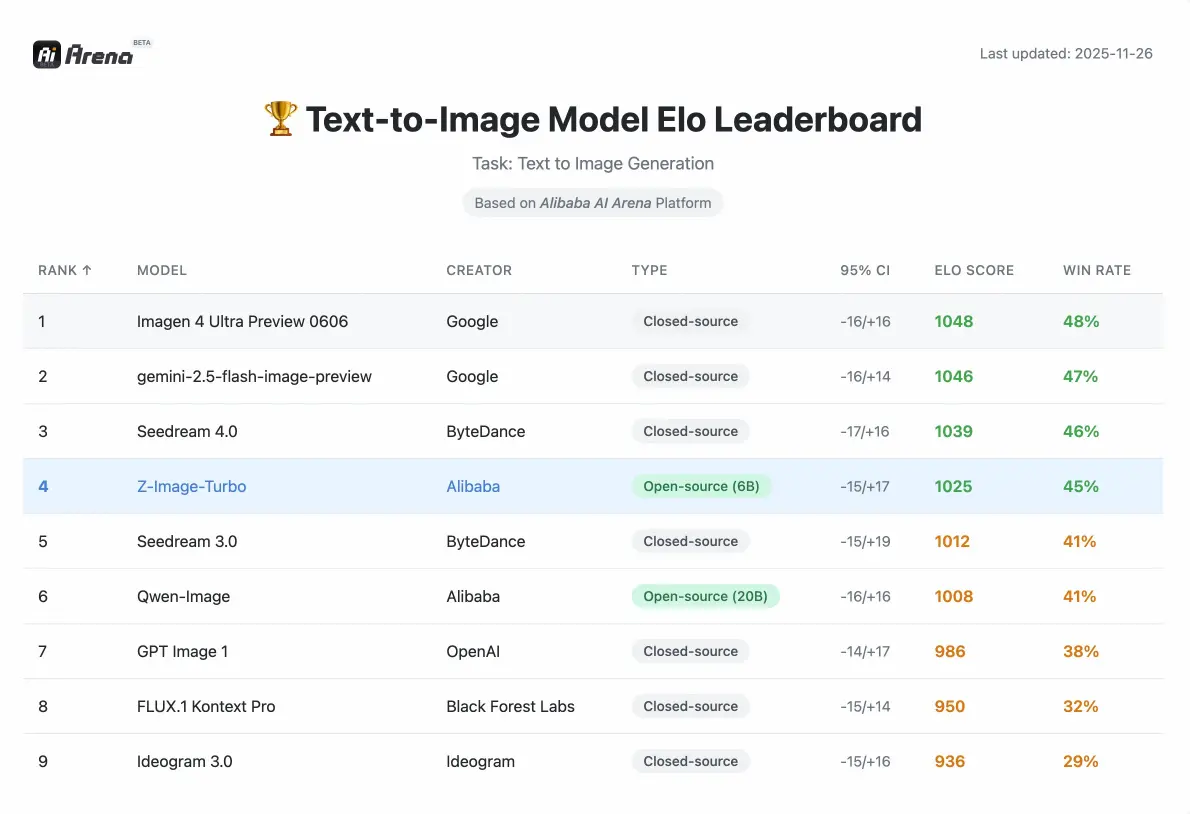
Rendimiento de imagen Z
Métricas competitivas validadas por evaluaciones de preferencias humanas en Alibaba AI Arena.
Parámetros
6B
Compacto pero Potente
Pasos (Turbo)
8
Generación Rápida
VRAM Requerida
<16GB
Hardware de Consumo
Lo que dicen los creadores sobre Z-Image
Experiencias de diseñadores, desarrolladores y creadores de contenido que usan nuestras herramientas.
David
Diseñador Gráfico
La calidad fotorrealista rivaliza con herramientas comerciales costosas. Lo integré en mi pipeline de ComfyUI en minutos.
Rachel
Creadora de Contenido
El renderizado de texto bilingüe es revolucionario. Los caracteres chinos salen nítidos sin ningún postprocesamiento.
Marcus
Desarrollador
Descargué la versión GGUF de Huggingface y la tenía funcionando localmente esa misma tarde. Muy sencillo.
Sofia
Directora de Marketing
La variante Edit sigue instrucciones complejas con precisión. Lo usamos para ajustes rápidos en las fotografías del producto.
James
E-commerce
La comprensión de composición de escenas es excelente. Los fondos de productos parecen fotografiados profesionalmente.
Anna
Artista
La precisión cultural me impresionó. Generó monumentos específicos y elementos tradicionales sin alucinaciones.
Preguntas frecuentes sobre Z-Imagen
Todo lo que necesita saber sobre Z-Image, la integración de ComfyUI y la descarga desde Huggingface.
¿Qué es exactamente Z-Imagen?
Z-Image es un modelo básico eficiente de 6 mil millones de parámetros para generar imágenes. Construido sobre una arquitectura de transformador de difusión de flujo único, ofrece calidad fotorrealista y representación de texto bilingüe comparable a las principales soluciones comerciales, sin requerir recursos computacionales masivos.
¿Cómo funciona la arquitectura Single-Stream Diffusion?
Esta arquitectura unifica el procesamiento de incrustaciones de texto, entradas condicionales y latentes ruidosos en una sola secuencia alimentada al backbone del transformer. Este enfoque simplificado mejora la eficiencia mientras mantiene alta calidad de salida, permitiendo que el modelo funcione en hardware de consumo.
¿Qué es Z-Image-Turbo?
Z-Image-Turbo es una variante destilada optimizada para la velocidad. Logra una generación fotorrealista con una representación precisa de texto bilingüe en solo 8 pasos de inferencia, entregando resultados comparables o superiores a los de los competidores que requieren muchos más pasos.
¿Qué es Z-Image-Edit?
Z-Image-Edit es una variante de capacitación continua especializada para modificar imágenes existentes. Se destaca por seguir instrucciones complejas para tareas que van desde ajustes locales precisos hasta transformaciones de estilo globales mientras mantiene la coherencia de la edición.
¿Puedo usar esto con ComfyUI?
Sí. El modelo se integra nativamente con ComfyUI a través de nodos personalizados. Puedes construir flujos de trabajo complejos que combinan generación, edición y postprocesamiento, todo dentro de la interfaz de ComfyUI. Hay plantillas de flujo de trabajo creadas por la comunidad disponibles para ayudarte a comenzar rápidamente.
¿Dónde puedo descargar los pesos?
Los pesos de los modelos están disponibles tanto en Huggingface como en ModelScope. Puede descargar el modelo base, la variante Turbo o la variante Editar según su caso de uso. También se proporcionan versiones cuantificadas de GGUF y FP8 para una implementación local eficiente.
¿Qué hardware necesito para ejecutarlo localmente?
El modelo funciona sin problemas en tarjetas gráficas de consumo con menos de 16GB de VRAM. Esto hace que la tecnología de generación avanzada sea accesible sin requerir hardware profesional costoso. Las versiones cuantizadas GGUF y FP8 reducen aún más los requisitos de memoria.
¿Admite texto en chino en las imágenes generadas?
Sí. El modelo tiene excelentes capacidades de renderizado bilingüe para texto tanto en chino como en inglés. Puede colocar texto con precisión dentro de las imágenes mientras mantiene la composición estética y legibilidad, incluso en tamaños de fuente pequeños.
¿Cómo se compara el rendimiento con otros modelos de código abierto?
Según la Evaluación de Preferencia Humana basada en Elo en Alibaba AI Arena, este modelo muestra un rendimiento altamente competitivo frente a alternativas líderes y logra resultados de vanguardia entre las opciones de código abierto en su clase de parámetros.
¿Qué es el Prompt Enhancer?
El Prompt Enhancer (PE) utiliza una cadena de razonamiento estructurada para inyectar lógica y sentido común en el proceso de generación. Esto permite manejar tareas complejas como el problema del pollo y el conejo o visualizar poesía clásica con coherencia lógica.
¿Es el modelo realmente de código abierto?
Sí. El código, los pesos y una demostración en línea están disponibles públicamente. El objetivo es promover el desarrollo de modelos generativos accesibles, de bajo costo y alto rendimiento que beneficien a toda la comunidad de investigación y desarrollo.
¿Puede manejar instrucciones complejas de múltiples partes?
La variante Edit sobresale particularmente aquí. Puede ejecutar instrucciones compuestas, como modificar simultáneamente la expresión y la pose de un personaje mientras agrega texto específico, manteniendo la coherencia en todos los cambios.
¿Cómo se implementa el entendimiento cultural?
El modelo posee un vasto conocimiento de monumentos mundiales, figuras históricas, conceptos culturales y objetos específicos del mundo real. Esto permite la generación precisa de diversos temas sin alucinaciones o imprecisiones culturales.
¿Qué hace especial el renderizado de texto?
Además del soporte bilingüe, el modelo demuestra fuertes habilidades tipográficas para diseño de carteles y composiciones complejas. Maneja escenarios desafiantes como tamaños de fuente pequeños o diseños intrincados mientras mantiene precisión textual y atractivo visual.
¿Cómo lo integro en mi pipeline existente?
Para usuarios de ComfyUI, simplemente descarga los nodos personalizados y carga los pesos. Para acceso programático, el modelo sigue las APIs estándar de modelos de difusión. La documentación incluye código de ejemplo para integración con Python, endpoints API y plantillas de flujo de trabajo.
¿Qué pasa con las versiones FP8 y GGUF?
Estas son versiones cuantizadas optimizadas para implementación eficiente. FP8 mantiene alta calidad con precisión reducida, mientras que GGUF proporciona máxima compatibilidad para inferencia local. Ambas reducen los requisitos de VRAM por debajo del modelo base.
¿Puedo usarlo para proyectos comerciales?
El modelo se lanza como código abierto con una licencia permisiva. Consulta los detalles específicos de la licencia en la página del repositorio para pautas de uso comercial. La mayoría de las aplicaciones comerciales estándar están permitidas.
¿Cómo se compara con Stable Diffusion?
Aunque ambos están basados en difusión, este modelo utiliza una arquitectura Single-Stream distintiva que unifica el procesamiento. Destaca particularmente en el renderizado de texto bilingüe y seguimiento de instrucciones, áreas donde los modelos estándar de Stable Diffusion a menudo tienen dificultades.
¿Qué resolución admite?
El modelo base admite resoluciones estándar optimizadas para equilibrio entre calidad y velocidad. Resoluciones más altas son alcanzables a través del flujo de trabajo de ComfyUI con nodos de escalado apropiados. Consulta la documentación para configuraciones de resolución recomendadas.
¿Hay un API disponible?
Sí. Se proporcionan tanto una demostración web como acceso API programático. Puedes integrar capacidades de generación directamente en tus aplicaciones sin gestionar infraestructura local si lo prefieres.
¿Con qué frecuencia se actualiza el modelo?
El equipo de desarrollo mantiene y mejora activamente el modelo. Las actualizaciones incluyen optimizaciones de rendimiento, capacidades ampliadas y funciones solicitadas por la comunidad. Sigue el repositorio para anuncios.
¿Puede generar rostros con precisión?
El modelo produce rasgos faciales altamente realistas con control fino sobre expresiones y detalles. Combinado con capacidades precisas de superposición de texto, es particularmente adecuado para contenido basado en retratos y materiales de marketing.
¿Qué hay sobre transferencia de estilo y efectos artísticos?
La variante Editar maneja transformaciones de estilo preservando la identidad del sujeto. Puede aplicar efectos artísticos, cambiar fondos o modificar la estética manteniendo la coherencia en los elementos visuales principales.
¿Cómo funcionan las adaptaciones LoRA con este modelo?
Los pesos LoRA personalizados pueden ser entrenados y aplicados para especializar el modelo en estilos o sujetos particulares. La arquitectura admite métodos de integración LoRA estándar familiares para usuarios de otros modelos de difusión.
¿Qué lo hace eficiente comparado con modelos más grandes?
La optimización sistemática a nivel de arquitectura permite que 6B parámetros igualen las salidas de modelos 10 veces más grandes. Esta eficiencia se traduce en inferencia más rápida, menores requisitos de hardware y costos operativos reducidos.
¿Hay soporte de la comunidad disponible?
Sí. Existen comunidades activas en Discord, GitHub y foros donde los usuarios comparten flujos de trabajo, resuelven problemas y muestran creaciones. El equipo de desarrollo interactúa regularmente con los comentarios de la comunidad.
¿Cómo reporto errores o solicito funciones?
El repositorio de GitHub acepta issues para reportes de errores y solicitudes de funciones. La participación de la comunidad ayuda a priorizar mejoras y asegura que el modelo evolucione para satisfacer las necesidades de los usuarios.
¿Pueden los principiantes usar esto sin conocimientos técnicos?
La demostración web proporciona una interfaz sin código para uso inmediato. Para implementación local, ComfyUI ofrece construcción visual de flujos de trabajo sin programación. Los usuarios técnicos pueden acceder al API completo para control programático.
¿Qué distingue esto de los modelos de imagen basados en Qwen?
Si bien Qwen se centra en la comprensión visión-lenguaje, este modelo se especializa en la generación con fortalezas únicas en la representación de texto bilingüe y la edición siguiendo instrucciones. Ambos pueden complementarse entre sí en procesos integrales de IA.
¿Se admite procesamiento por lotes?
Sí. Tanto el API como los flujos de trabajo de ComfyUI admiten generación por lotes para procesar múltiples prompts de manera eficiente. Esto es útil para entornos de producción que requieren alto rendimiento.
Comience a crear con Z-Image
Experimenta la generación eficiente con este modelo fundamental de código abierto. Uso gratuito.