de plus de 52472 utilisateurs satisfaits
Z-Image Turbo
Générateur d'images Z-Image Turbo AI gratuit en ligne, le modèle d'IA d'image 6B Z de Tongyi-MAI. Créez et modifiez des images avec Z Image Turbo et Z-Image-Edit.
Générateur d'images Z-Image Turbo AI
Générez et modifiez des images avec des invites de texte ou des images par Z-Image Turbo AI

Galerie d'inspiration Z-Image
Explorez ce qui est possible grâce aux capacités de génération Z-Image Turbo. Cliquez sur n’importe quel élément pour afficher les invites Z-Image.






![[Art Style & Viewpoint]:
Hyper-realistic 8k product photography, macro lens perspective, strict 90-degree overhead flat-lay (knolling).
[Aesthetic Philosophy]: "Sublime Micro-Engineering Narratives". A blend of surgical precision and artistic interpretation of technical components.
[Subject Input]:
Target Object: Deconstructed Leica M3 Camera Body
[Action]: Forensic Technical Exploded View. Disassemble into 8-12 primary components, but with an emphasis on secondary and tertiary sub-components (e.g., individual gears within a gearbox, micro-switches on a circuit board, specific spring types, internal wiring harnesses).
[Detail Emphasis]: Each component is meticulously rendered.
Metals: Highlight brushed grains, polished edges, anodic oxidation sheen, laser-etched serial numbers or specific alloy markings. Show microscopic tolerances between parts.
Plastics: Reveal injection molding marks, precise seam lines, and subtle textural variations.
Circuitry: Emphasize the solder joints, traces, tiny capacitors, and integrated chip details.
Glass/Optics: Render reflections, anti-reflective coatings, and subtle refractions.
[Background]: Premium matte cool-grey workbench surface.
[Interactive Schematics]: Ultra-fine Cyan/Tech-Blue vector lines. Include cross-sectional views, exploded assembly sequence lines (dashed arrows), and material call-outs (e.g., "Alloy 7075", "Carbon Fiber Weave").
[Artistic Title Style]: "Industrial Stencil" Aesthetic. Large, bold, semi-transparent text (e.g., "PROJECT: ALPHA" or "ENGINE MODEL: X9") laser-etched onto the background surface.](https://pub-eb5b81bfee5c4e39ba2d1f7195360ef2.r2.dev/inspiration/7.jpeg)













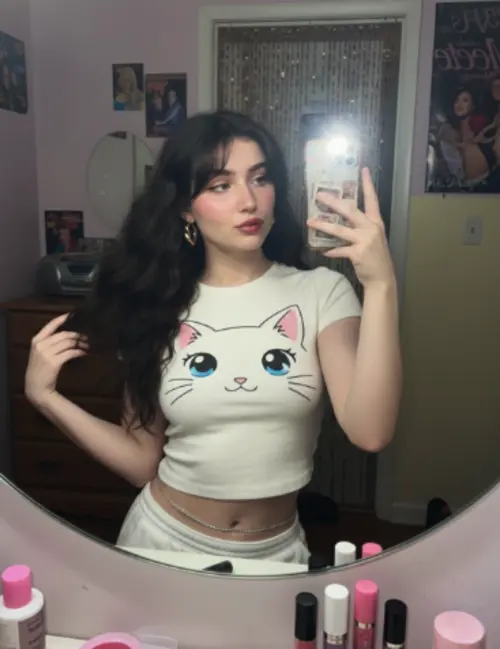




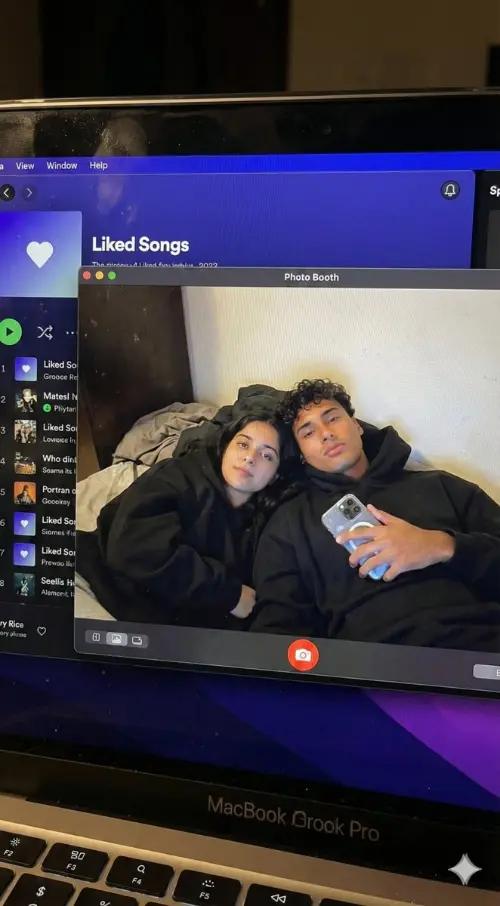
Comparaison des résultats de différents modèles
Découvrez comment différents modèles d'IA génèrent des résultats variés avec le même prompt.
Image originale

Générez une photo très détaillée d'une fille cosplayant cette illustration, sur Comiket. Reproduisez exactement la même pose, la même posture du corps, les mêmes gestes de la main, l'expression du visage et le même cadrage de la caméra que dans l'illustration originale. Gardez le même angle, la même perspective et la même composition, sans aucun écart
Résultats générés

Flux Pro

Qwen

Seedream

Nano Banana













Modèles

Nano Banana 2
NouveauDernière génération avec une qualité améliorée
Nano Banana
En vedetteCohérence des personnages ultra-élevée

Seedream
NouveauPrise en charge d'images aux styles cohérents

Flux Dev
Pour des scènes courtes et simples

Qwen
NouveauExcellent pour le rendu de texte complexe
Flux Schnell Lora
NouveauGénération d'images rapide et créative
Flux Kontext
Pour le photoréalisme et le contrôle créatif
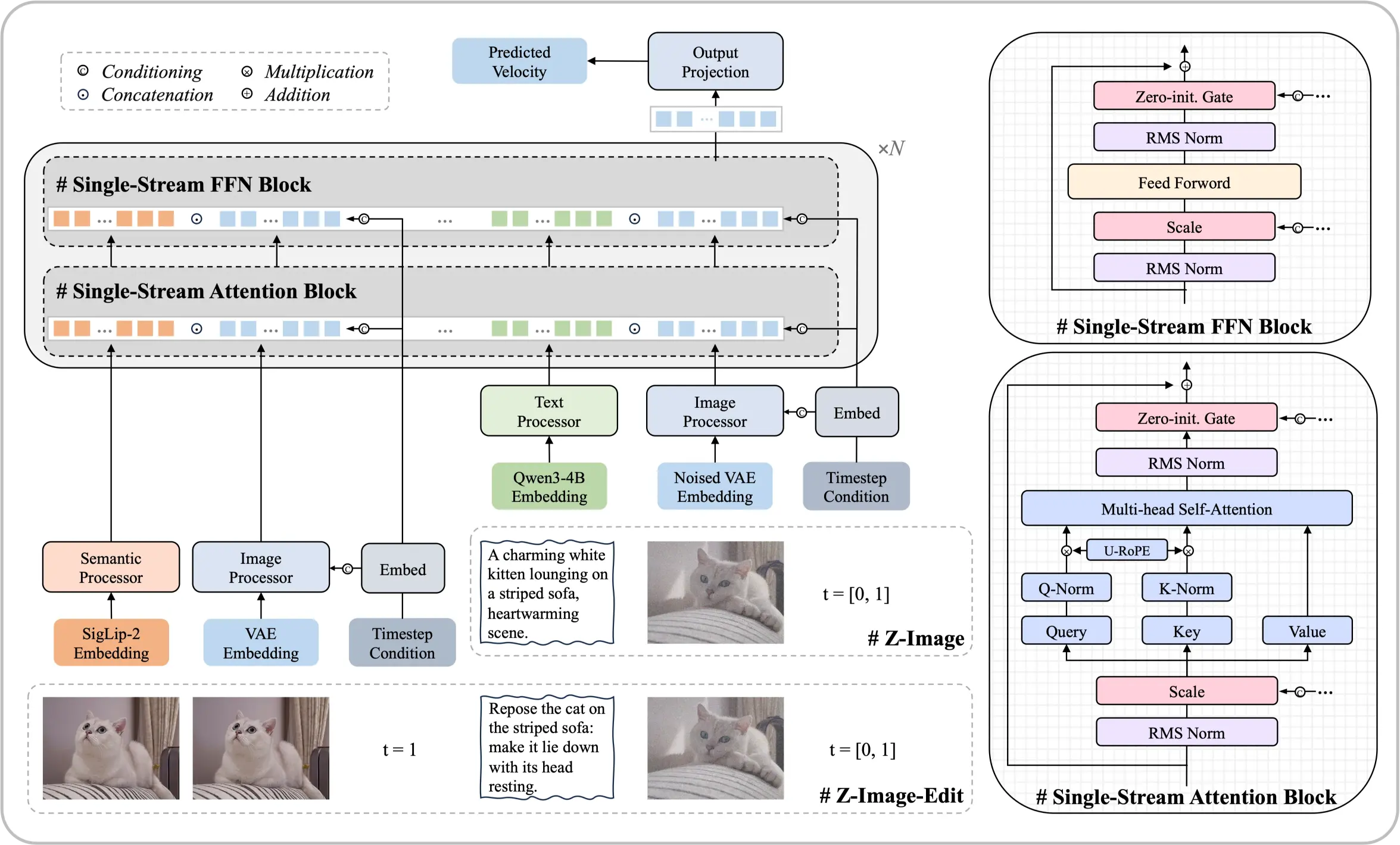
Découvrez le modèle de fondation Z-Image
Une architecture de 6 milliards de paramètres qui prouve que des résultats de premier ordre sont réalisables sans ressources de calcul massives. Ce modèle de diffusion open source produit des rendus photoréalistes et un rendu de texte bilingue comparables aux meilleures solutions commerciales.
- Architecture à flux uniqueUnifie les embeddings de texte et le traitement des latents dans une seule séquence de transformateur efficace.
- Réalisme photographiqueContrôle précis de l'éclairage, des textures et des détails qui correspondent aux standards professionnels.
- Texte chinois et anglaisRendu précis du texte bilingue directement dans les visuels générés.
Points forts du modèle
Une optimisation systématique permet des performances rivalisant avec des modèles dix fois plus grands.
Premiers pas avec Z-Image
Créez des visuels époustouflants en quatre étapes simples :
Ce qui distingue Z-Image
Explorez les capacités qui font de Z-Image un leader parmi les alternatives open source.
Intégration ComfyUI
Les nœuds Z-Image fournissent une prise en charge native du flux de travail pour une création de pipeline transparente.
Typographie professionnelle
Compétences compositionnelles solides pour la conception d'affiches avec un placement de texte précis.
Instructions multi-étapes
Suit des prompts composites complexes avec cohérence logique.
Équilibre esthétique
Visuels haute fidélité avec une composition et une ambiance agréables.
Huggingface et ModelScope
Poids disponibles en téléchargement sur les principaux dépôts de modèles.
Formats GGUF et FP8
Versions quantifiées optimisées pour un déploiement local efficace.
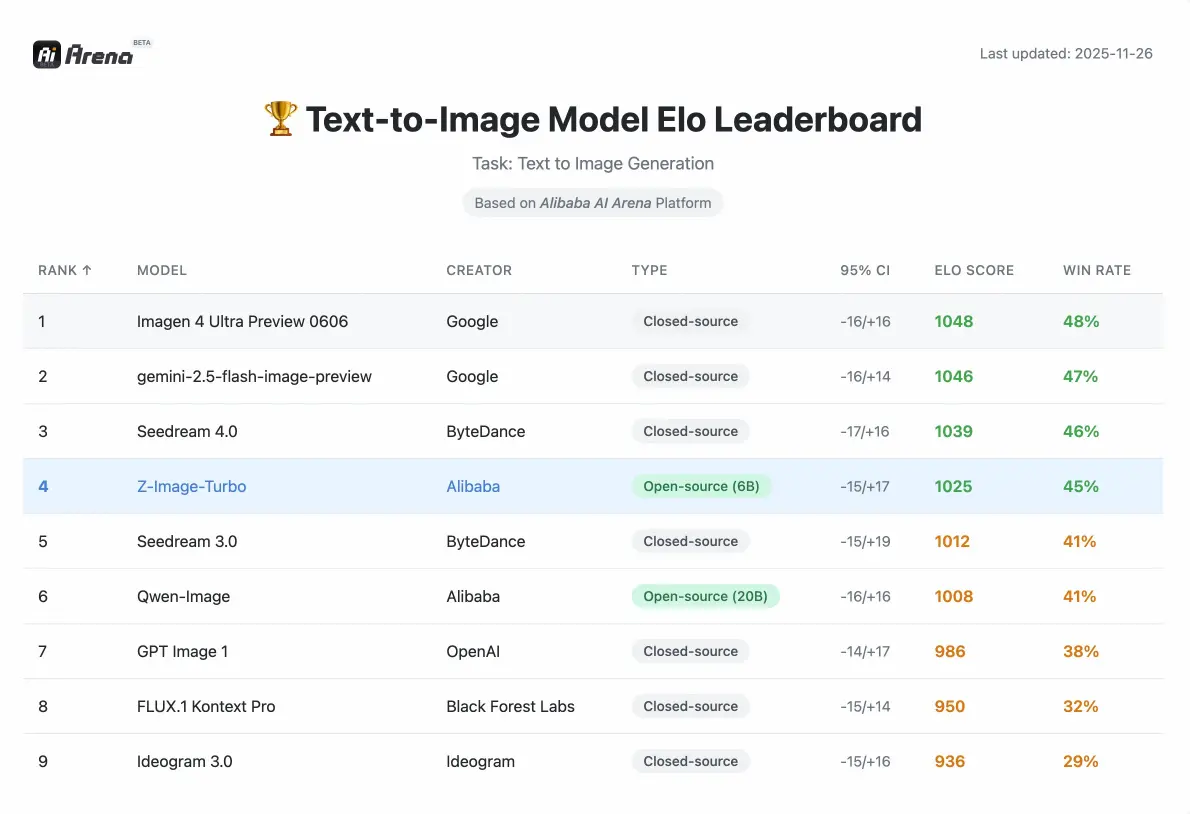
Performances de l'image Z
Mesures compétitives validées par les évaluations des préférences humaines sur Alibaba AI Arena.
Paramètres
6B
Compact mais puissant
Étapes (Turbo)
8
Génération rapide
VRAM requise
<16GB
Matériel grand public
Ce que disent les créateurs à propos de Z-Image
Expériences de designers, développeurs et créateurs de contenu utilisant nos outils.
David
Designer graphique
La qualité photoréaliste rivalise avec les outils commerciaux coûteux. Je l'ai intégré à mon pipeline ComfyUI en quelques minutes.
Rachel
Créatrice de contenu
Le rendu de texte bilingue change la donne. Les caractères chinois ressortent nets sans aucun post-traitement.
Marcus
Développeur
J'ai téléchargé la version GGUF depuis Huggingface et je l'ai fait fonctionner localement le même après-midi. Très simple.
Sofia
Directrice marketing
La variante Edit suit avec précision des instructions complexes. Nous l'utilisons pour des ajustements rapides des photos de produits.
James
E-commerce
La compréhension de la composition de scène est excellente. Les arrière-plans de produits semblent photographiés professionnellement.
Anna
Artiste
L'exactitude culturelle m'a impressionnée. Il a généré des monuments spécifiques et des éléments traditionnels sans hallucinations.
Foire aux questions sur Z-Image
Tout ce que vous devez savoir sur Z-Image, l'intégration de ComfyUI et le téléchargement depuis Huggingface.
Qu’est-ce que Z-Image exactement ?
Z-Image est un modèle de base efficace de 6 milliards de paramètres pour générer des visuels. Construit sur une architecture de transformateur de diffusion à flux unique, il offre une qualité photoréaliste et un rendu de texte bilingue comparable aux principales solutions commerciales, sans nécessiter d'énormes ressources informatiques.
Comment fonctionne l'architecture Single-Stream Diffusion ?
Cette architecture unifie le traitement des embeddings de texte, des entrées conditionnelles et des latents bruités dans une seule séquence alimentant le backbone du transformateur. Cette approche rationalisée améliore l'efficacité tout en maintenant une haute qualité de sortie, permettant au modèle de fonctionner sur du matériel grand public.
Qu’est-ce que Z-Image-Turbo ?
Z-Image-Turbo est une variante distillée optimisée pour la vitesse. Il permet une génération photoréaliste avec un rendu de texte bilingue précis en seulement 8 étapes d'inférence, fournissant des résultats comparables ou supérieurs à ceux de ses concurrents qui nécessitent beaucoup plus d'étapes.
Qu'est-ce que Z-Image-Edit ?
Z-Image-Edit est une variante de formation continue spécialisée dans la modification de visuels existants. Il excelle dans le suivi d'instructions complexes pour des tâches allant des ajustements locaux précis aux transformations de style globales tout en conservant la cohérence des modifications.
Puis-je l'utiliser avec ComfyUI ?
Oui. Le modèle s'intègre nativement avec ComfyUI via des nœuds personnalisés. Vous pouvez construire des flux de travail complexes combinant génération, édition et post-traitement directement dans l'interface ComfyUI. Des modèles de flux de travail créés par la communauté sont disponibles pour vous aider à démarrer rapidement.
Où puis-je télécharger les poids ?
Les poids des modèles sont disponibles sur Huggingface et ModelScope. Vous pouvez télécharger le modèle de base, la variante Turbo ou la variante Edit en fonction de votre cas d'utilisation. Des versions quantifiées GGUF et FP8 sont également fournies pour un déploiement local efficace.
Quel matériel me faut-il pour l'exécuter localement ?
Le modèle fonctionne parfaitement sur des cartes graphiques grand public avec moins de 16 Go de VRAM. Cela rend la technologie de génération avancée accessible sans nécessiter de matériel professionnel coûteux. Les versions quantifiées GGUF et FP8 réduisent encore les besoins en mémoire.
Prend-il en charge le texte chinois dans les visuels générés ?
Oui. Le modèle possède d'excellentes capacités de rendu bilingue pour le texte chinois et anglais. Il peut placer avec précision le texte dans les visuels tout en maintenant la composition esthétique et la lisibilité, même pour de petites tailles de police.
Comment les performances se comparent-elles à d'autres modèles open source ?
Selon l'évaluation des préférences humaines basée sur Elo sur Alibaba AI Arena, ce modèle présente des performances hautement compétitives par rapport aux principales alternatives et obtient des résultats de pointe parmi les options open source dans sa classe de paramètres.
Qu'est-ce que le Prompt Enhancer ?
Le Prompt Enhancer (PE) utilise une chaîne de raisonnement structurée pour injecter de la logique et du bon sens dans le processus de génération. Cela permet de gérer des tâches complexes comme le problème de poules et de lapins ou la visualisation de poésie classique avec cohérence logique.
Le modèle est-il vraiment open source ?
Oui. Le code, les poids et une démo en ligne sont publiquement disponibles. L'objectif est de promouvoir le développement de modèles génératifs accessibles, à faible coût et haute performance qui bénéficient à l'ensemble de la communauté de recherche et de développement.
Peut-il gérer des instructions complexes en plusieurs parties ?
La variante Edit excelle particulièrement ici. Il peut exécuter des instructions composites telles que la modification simultanée de l'expression et de la pose d'un personnage tout en ajoutant un texte spécifique, en maintenant la cohérence entre toutes les modifications.
Comment la compréhension culturelle est-elle mise en œuvre ?
Le modèle possède une vaste connaissance des monuments mondiaux, des personnages historiques, des concepts culturels et des objets du monde réel spécifiques. Cela permet une génération précise de sujets divers sans hallucinations ou inexactitudes culturelles.
Qu'est-ce qui rend le rendu de texte spécial ?
Au-delà du support bilingue, le modèle démontre de solides compétences typographiques pour la conception d'affiches et les compositions complexes. Il gère des scénarios difficiles comme de petites tailles de police ou des mises en page complexes tout en maintenant la précision textuelle et l'attrait visuel.
Comment l'intégrer dans mon pipeline existant ?
Pour les utilisateurs de ComfyUI, téléchargez simplement les nœuds personnalisés et chargez les poids. Pour un accès programmatique, le modèle suit les APIs standard des modèles de diffusion. La documentation inclut des exemples de code pour l'intégration Python, les points de terminaison API et les modèles de flux de travail.
Qu'en est-il des versions FP8 et GGUF ?
Ce sont des versions quantifiées optimisées pour un déploiement efficace. FP8 maintient une haute qualité avec une précision réduite, tandis que GGUF offre une compatibilité maximale pour l'inférence locale. Les deux réduisent les besoins en VRAM par rapport au modèle de base.
Puis-je l'utiliser pour des projets commerciaux ?
Le modèle est publié en open source avec une licence permissive. Consultez les détails de licence spécifiques sur la page du dépôt pour les directives d'utilisation commerciale. La plupart des applications commerciales standard sont autorisées.
Comment se compare-t-il à Stable Diffusion ?
Bien que les deux soient basés sur la diffusion, ce modèle utilise une architecture Single-Stream distincte qui unifie le traitement. Il excelle particulièrement dans le rendu de texte bilingue et le suivi d'instructions, des domaines où les modèles Stable Diffusion standard peinent souvent.
Quelle résolution prend-il en charge ?
Le modèle de base prend en charge les résolutions standard optimisées pour l'équilibre qualité et vitesse. Des résolutions plus élevées sont réalisables via le flux de travail ComfyUI avec des nœuds d'upscaling appropriés. Consultez la documentation pour les paramètres de résolution recommandés.
Y a-t-il une API disponible ?
Oui. Une démo web et un accès programmatique via API sont fournis. Vous pouvez intégrer les capacités de génération directement dans vos applications sans gérer l'infrastructure locale si vous préférez.
À quelle fréquence le modèle est-il mis à jour ?
L'équipe de développement maintient et améliore activement le modèle. Les mises à jour incluent des optimisations de performance, des capacités étendues et des fonctionnalités demandées par la communauté. Suivez le dépôt pour les annonces.
Peut-il générer des visages avec précision ?
Le modèle produit des traits faciaux très réalistes avec un contrôle précis sur les expressions et les détails. Combiné à des capacités de superposition de texte précises, il est particulièrement adapté au contenu basé sur les portraits et aux supports marketing.
Qu'en est-il du transfert de style et des effets artistiques ?
La variante Edit gère les transformations de style tout en préservant l'identité du sujet. Vous pouvez appliquer des effets artistiques, changer d'arrière-plan ou modifier l'esthétique tout en conservant la cohérence des éléments visuels de base.
Comment les adaptations LoRA fonctionnent-elles avec ce modèle ?
Des poids LoRA personnalisés peuvent être entraînés et appliqués pour spécialiser le modèle pour des styles ou sujets particuliers. L'architecture prend en charge les méthodes d'intégration LoRA standard familières aux utilisateurs d'autres modèles de diffusion.
Qu'est-ce qui le rend efficace par rapport aux modèles plus grands ?
L'optimisation systématique au niveau de l'architecture permet à 6 milliards de paramètres d'égaler les sorties de modèles 10 fois plus grands. Cette efficacité se traduit par une inférence plus rapide, des exigences matérielles réduites et des coûts opérationnels diminués.
Un support communautaire est-il disponible ?
Oui. Des communautés actives existent sur Discord, GitHub et les forums où les utilisateurs partagent des flux de travail, résolvent des problèmes et présentent leurs créations. L'équipe de développement s'engage régulièrement avec les retours de la communauté.
Comment signaler des bugs ou demander des fonctionnalités ?
Le dépôt GitHub accepte les problèmes pour les rapports de bugs et les demandes de fonctionnalités. La participation de la communauté aide à prioriser les améliorations et garantit que le modèle évolue pour répondre aux besoins des utilisateurs.
Les débutants peuvent-ils l'utiliser sans connaissances techniques ?
La démo web fournit une interface sans code pour une utilisation immédiate. Pour un déploiement local, ComfyUI offre une construction de flux de travail visuel sans codage. Les utilisateurs techniques peuvent accéder à l'API complète pour un contrôle programmatique.
Qu'est-ce qui distingue cela des modèles d'images basés sur Qwen ?
Alors que Qwen se concentre sur la compréhension vision-langage, ce modèle se spécialise dans la génération avec des forces uniques dans le rendu de texte bilingue et l'édition suivant les instructions. Les deux peuvent se compléter dans des pipelines IA complets.
Le traitement par lots est-il pris en charge ?
Oui. L'API et les flux de travail ComfyUI prennent en charge la génération par lots pour traiter plusieurs prompts efficacement. Ceci est utile pour les environnements de production nécessitant un débit élevé.
Commencez à créer avec Z-Image
Découvrez la génération efficace avec ce modèle fondamental open source. Gratuit à utiliser.