52472人以上の満足したユーザーから
Zイメージターボ
無料のZ-Image Turbo AI画像生成ツール。Tongyi-MAIが開発した60億パラメータのZ-image AIモデル。Z-Image TurboとZ-Image-Editで画像の作成と編集を実現。
Z-Image Turbo AI画像ジェネレーター
Z-Image Turbo AIでテキストプロンプトや画像から画像を生成・編集

Z-Image インスピレーションギャラリー
Z-Image Turboの生成能力で何が可能かを探求しましょう。アイテムをクリックしてZ-Imageのプロンプトを表示します。






![[Art Style & Viewpoint]:
Hyper-realistic 8k product photography, macro lens perspective, strict 90-degree overhead flat-lay (knolling).
[Aesthetic Philosophy]: "Sublime Micro-Engineering Narratives". A blend of surgical precision and artistic interpretation of technical components.
[Subject Input]:
Target Object: Deconstructed Leica M3 Camera Body
[Action]: Forensic Technical Exploded View. Disassemble into 8-12 primary components, but with an emphasis on secondary and tertiary sub-components (e.g., individual gears within a gearbox, micro-switches on a circuit board, specific spring types, internal wiring harnesses).
[Detail Emphasis]: Each component is meticulously rendered.
Metals: Highlight brushed grains, polished edges, anodic oxidation sheen, laser-etched serial numbers or specific alloy markings. Show microscopic tolerances between parts.
Plastics: Reveal injection molding marks, precise seam lines, and subtle textural variations.
Circuitry: Emphasize the solder joints, traces, tiny capacitors, and integrated chip details.
Glass/Optics: Render reflections, anti-reflective coatings, and subtle refractions.
[Background]: Premium matte cool-grey workbench surface.
[Interactive Schematics]: Ultra-fine Cyan/Tech-Blue vector lines. Include cross-sectional views, exploded assembly sequence lines (dashed arrows), and material call-outs (e.g., "Alloy 7075", "Carbon Fiber Weave").
[Artistic Title Style]: "Industrial Stencil" Aesthetic. Large, bold, semi-transparent text (e.g., "PROJECT: ALPHA" or "ENGINE MODEL: X9") laser-etched onto the background surface.](https://pub-eb5b81bfee5c4e39ba2d1f7195360ef2.r2.dev/inspiration/7.jpeg)

















異なるモデルの生成結果の比較
同じプロンプトで異なるAIモデルがどのように異なる結果を生成するかをご覧ください。
元の画像

コミケでこのイラストをコスプレした女の子の高精細な写真を生成してください。元のイラストと全く同じポーズ、体の姿勢、手のジェスチャー、表情、カメラフレーミングを正確に再現してください。同じ角度、視点、構図を維持し、一切の偏差なく。
生成結果

Flux Pro

Qwen

Seedream

Nano Banana













モデル

Nano Banana 2
新着品質が向上した最新世代
Nano Banana
おすすめ超高キャラクター一貫性

Seedream
新着一貫性のあるスタイルの画像をサポート

Flux Dev
短くシンプルなシーンに最適

Qwen
新着複雑なテキストレンダリングが得意
Flux Schnell Lora
新着高速でクリエイティブな画像生成
Flux Kontext
フォトリアリズムとクリエイティブコントロール用
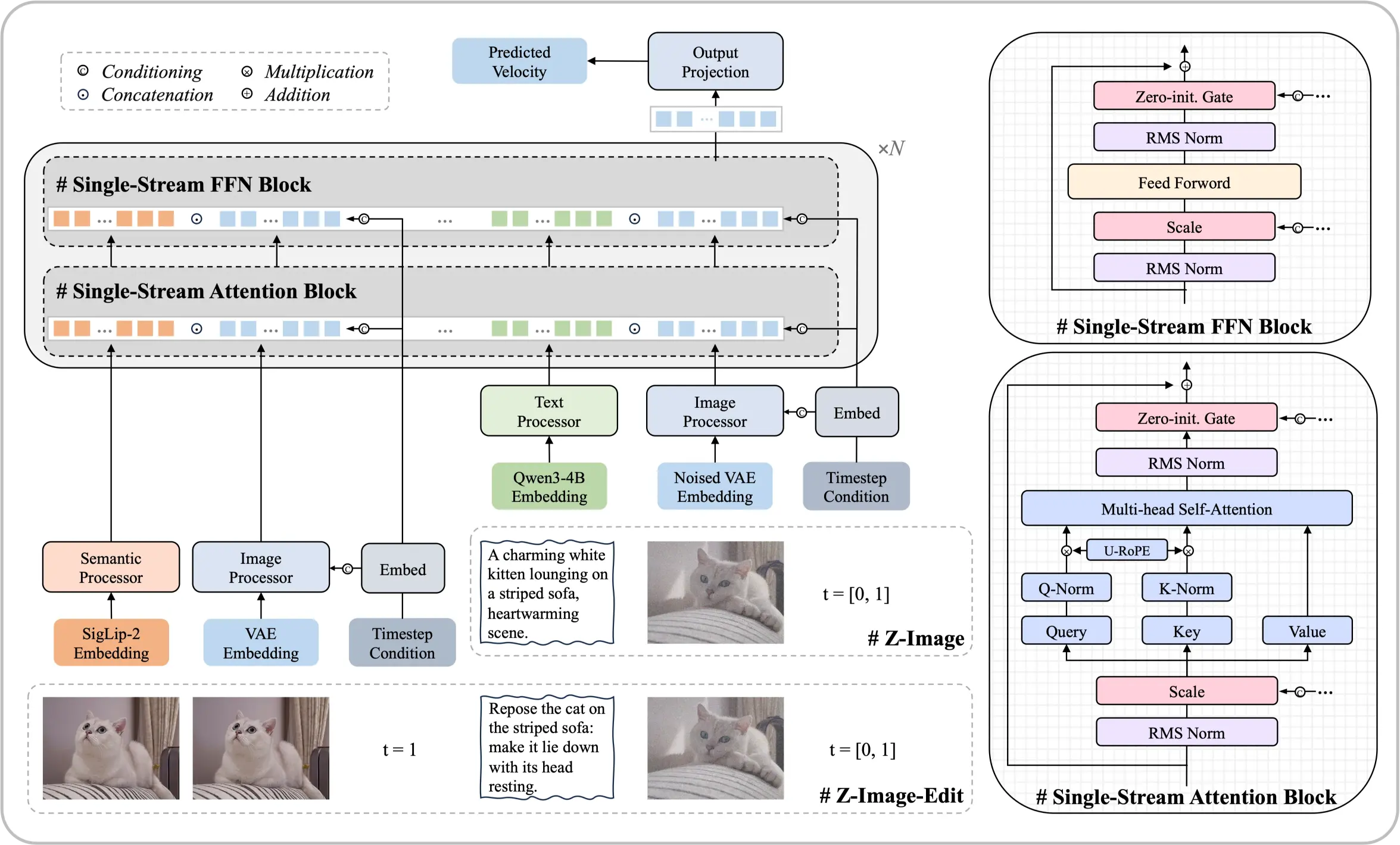
Z-Image基盤モデルのご紹介
60億パラメータのアーキテクチャで、大規模な計算リソースなしに最高水準の結果を実現。このオープンソース拡散モデルは、主要な商用ソリューションに匹敵するフォトリアルな出力と多言語テキストレンダリングを提供します。
- シングルストリームアーキテクチャテキスト埋め込みと潜在的処理を1つの効率的なトランスフォーマーシーケンスに統合。
- 写真レベルのリアリズムプロフェッショナル基準に合う照明、質感、ディテールを精密にコントロール。
- 中国語・英語テキスト生成されたビジュアル内で多言語テキストを正確にレンダリング。
モデルの主要な強み
体系的な最適化により、1桁大きいモデルに匹敵するパフォーマンスを実現。
Z-Imageの使い方
4つの簡単なステップで素晴らしいビジュアルを作成:
Z-Imageの特徴
Z-Imageをオープンソースの代替品の中でリーダーにする機能をご覧ください。
ComfyUI統合
Z-Imageノードがシームレスなパイプラインビルドのためのネイティブワークフローサポートを提供。
プロフェッショナルタイポグラフィ
正確なテキスト配置でポスターデザインのための強力な構図スキル。
マルチステップ指示
論理的な一貫性を持って複雑な複合プロンプトに従います。
美的バランス
美しい構図とムードを持つ高忠実度のビジュアル。
HuggingfaceとModelScope
主要なモデルリポジトリでダウンロード可能なウェイト。
GGUFとFP8形式
効率的なローカルデプロイメントのための最適化された量子化バージョン。
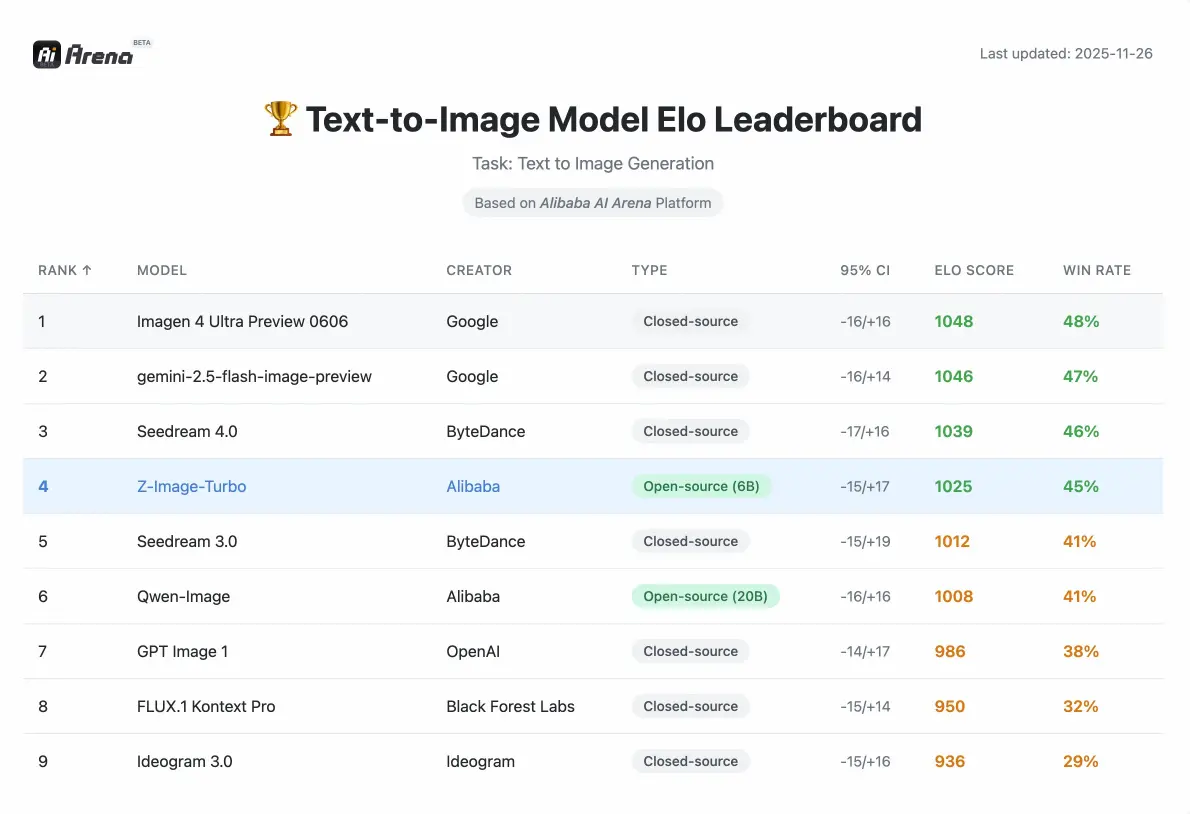
Z-Imageのパフォーマンス
Alibaba AI Arenaの人間による選好評価で検証された競争力のある指標。
パラメータ数
60億
コンパクトでパワフル
ステップ数(Turbo)
8
高速生成
必要なVRAM
<16GB
コンシューマーハードウェア
クリエイターの声
Z-Imageを使用しているデザイナー、開発者、コンテンツクリエイターの体験談。
David
グラフィックデザイナー
フォトリアルな品質は高価な商用ツールに匹敵します。数分でComfyUIパイプラインに統合できました。
Rachel
コンテンツクリエイター
多言語テキストレンダリングはゲームチェンジャーです。中国語の文字が後処理なしで鮮明に出力されます。
Marcus
開発者
HuggingfaceからGGUFバージョンをダウンロードし、同じ午後にローカルで実行できました。非常に簡単でした。
Sofia
マーケティングディレクター
Editバリアントは複雑な指示に正確に従います。製品写真の迅速な調整に使用しています。
James
Eコマース
シーン構成の理解が優れています。製品の背景がプロの撮影のように見えます。
Anna
アーティスト
文化的な正確性に感銘を受けました。特定のランドマークや伝統的な要素を幻覚なしで生成しました。
Z-Imageについてのよくある質問
Z-Image、ComfyUI統合、Huggingfaceからのダウンロードについて知っておくべきすべて。
Z-Imageとは何ですか?
Z-Imageは、ビジュアル生成のための効率的な60億パラメータの基盤モデルです。シングルストリーム拡散トランスフォーマーアーキテクチャに基づいており、大規模な計算リソースを必要とせずに、主要な商用ソリューションに匹敵するフォトリアルな品質と多言語テキストレンダリングを提供します。
シングルストリーム拡散アーキテクチャはどのように機能しますか?
このアーキテクチャは、テキスト埋め込み、条件付き入力、ノイズの多い潜在変数の処理を、トランスフォーマーバックボーンに供給される単一のシーケンスに統合します。この合理化されたアプローチにより、高い出力品質を維持しながら効率が向上し、コンシューマーグレードのハードウェアでモデルを実行できます。
Z-Image-Turboとは何ですか?
Z-Image-Turboは、速度のために最適化された蒸留バリアントです。わずか8推論ステップで、正確な多言語テキストレンダリングを備えたフォトリアルな生成を実現し、より多くのステップを必要とする競合製品と同等以上の結果を提供します。
Z-Image-Editとは何ですか?
Z-Image-Editは、既存のビジュアルの修正に特化した継続トレーニングバリアントです。精密なローカル調整からグローバルスタイル変換まで、編集の一貫性を維持しながら複雑な指示に従うことに優れています。
ComfyUIで使用できますか?
はい。モデルはカスタムノードを通じてComfyUIとネイティブに統合されます。生成、編集、後処理を組み合わせた複雑なワークフローをComfyUIインターフェース内で構築できます。コミュニティが作成したワークフローテンプレートは、素早く開始するのに役立ちます。
ウェイトはどこでダウンロードできますか?
モデルウェイトはHuggingfaceとModelScopeの両方で利用できます。使用ケースに応じて、基本モデル、Turboバリアント、またはEditバリアントをダウンロードできます。効率的なローカルデプロイメントのためのGGUFおよびFP8量子化バージョンも提供されています。
ローカルで実行するにはどのようなハードウェアが必要ですか?
モデルは16GB未満のVRAMを搭載したコンシューマーグレードのグラフィックカードでスムーズに動作します。これにより、高価なプロフェッショナルハードウェアを必要とせずに高度な生成技術にアクセスできます。量子化されたGGUFおよびFP8バージョンは、メモリ要件をさらに削減します。
生成されたビジュアルで中国語テキストをサポートしていますか?
はい。モデルは中国語と英語のテキストの両方に優れた多言語レンダリング機能を備えています。小さいフォントサイズでも、美的構成と読みやすさを維持しながら、ビジュアル内にテキストを正確に配置できます。
他のオープンソースモデルと比較してパフォーマンスはどうですか?
Alibaba AI ArenaのEloベースの人間選好評価によると、このモデルは主要な代替案に対して非常に競争力のあるパフォーマンスを示し、そのパラメータクラスのオープンソースオプションの中で最先端の結果を達成しています。
プロンプトエンハンサーとは何ですか?
プロンプトエンハンサー(PE)は、構造化された推論チェーンを使用して、生成プロセスにロジックと常識を注入します。これにより、鶏とウサギの問題や古典詩の視覚化などの複雑なタスクを論理的な一貫性で処理できます。
モデルは本当にオープンソースですか?
はい。コード、ウェイト、オンラインデモが公開されています。目標は、研究および開発者コミュニティ全体に利益をもたらす、アクセス可能で低コストで高性能な生成モデルの開発を促進することです。
複雑な複数部分の指示を処理できますか?
Editバリアントは特にこの点で優れています。キャラクターの表情とポーズを同時に変更しながら特定のテキストを追加するなど、すべての変更で一貫性を維持しながら複合指示を実行できます。
文化的理解はどのように実装されていますか?
モデルは、世界のランドマーク、歴史上の人物、文化的概念、特定の実在する物体に関する広範な知識を持っています。これにより、幻覚や文化的な不正確さなしに、多様な主題を正確に生成できます。
テキストレンダリングの特別な点は何ですか?
多言語サポートに加えて、モデルはポスターデザインや複雑な構成のための強力なタイポグラフィスキルを示します。小さいフォントサイズや複雑なレイアウトなどの困難なシナリオを、テキストの精度と視覚的魅力を維持しながら処理します。
既存のパイプラインに統合するにはどうすればよいですか?
ComfyUIユーザーの場合、カスタムノードをダウンロードしてウェイトを読み込むだけです。プログラムによるアクセスの場合、モデルは標準的な拡散モデルAPIに従います。ドキュメントには、Python統合、APIエンドポイント、ワークフローテンプレートのサンプルコードが含まれています。
FP8およびGGUFバージョンについて教えてください。
これらは、効率的なデプロイメントのために最適化された量子化バージョンです。FP8は精度を下げて高品質を維持し、GGUFはローカル推論の最大互換性を提供します。どちらもベースモデルよりVRAM要件を削減します。
商用プロジェクトに使用できますか?
モデルは寛容なライセンスでオープンソースとしてリリースされています。商用利用のガイドラインについては、リポジトリページの具体的なライセンスの詳細を確認してください。ほとんどの標準的な商用アプリケーションが許可されています。
Stable Diffusionと比較してどうですか?
どちらも拡散ベースですが、このモデルは処理を統合する独特のシングルストリームアーキテクチャを使用しています。特に多言語テキストレンダリングと指示フォローの分野で優れており、これらは標準のStable Diffusionモデルがしばしば苦戦する領域です。
どの解像度をサポートしていますか?
ベースモデルは、品質と速度のバランスに最適化された標準解像度をサポートしています。より高い解像度は、適切なアップスケーリングノードを使用してComfyUIワークフローを通じて達成できます。推奨される解像度設定についてはドキュメントを確認してください。
APIは利用できますか?
はい。WebデモとプログラムによるAPIアクセスの両方が提供されています。必要に応じて、ローカルインフラストラクチャを管理することなく、生成機能をアプリケーションに直接統合できます。
モデルはどのくらいの頻度で更新されますか?
開発チームはモデルを積極的に維持および改善しています。更新には、パフォーマンスの最適化、機能の拡張、コミュニティが要求する機能が含まれます。アナウンスについてはリポジトリをフォローしてください。
顔を正確に生成できますか?
モデルは、表情とディテールを細かくコントロールして非常にリアルな顔の特徴を生成します。正確なテキストオーバーレイ機能と組み合わせて、ポートレートベースのコンテンツやマーケティング資料に特に適しています。
スタイル転送と芸術的効果について教えてください。
Editバリアントは、被写体のアイデンティティを保持しながらスタイル変換を処理します。コアビジュアル要素の一貫性を維持しながら、芸術的効果を適用したり、背景を変更したり、美学を変更したりできます。
LoRA適応はこのモデルでどのように機能しますか?
カスタムLoRAウェイトをトレーニングして適用し、特定のスタイルや被写体に対してモデルを専門化できます。アーキテクチャは、他の拡散モデルのユーザーに馴染みのある標準的なLoRA統合方法をサポートしています。
大規模モデルと比較して効率的な理由は何ですか?
アーキテクチャレベルでの体系的な最適化により、60億パラメータで10倍大きいモデルからの出力に匹敵することができます。この効率性は、より高速な推論、より低いハードウェア要件、より低い運用コストに変換されます。
コミュニティサポートは利用できますか?
はい。Discord、GitHub、フォーラムにアクティブなコミュニティが存在し、ユーザーがワークフローを共有し、問題をトラブルシューティングし、作品を紹介しています。開発チームはコミュニティのフィードバックに定期的に関与しています。
バグを報告したり機能をリクエストしたりするにはどうすればよいですか?
GitHubリポジトリは、バグレポートと機能リクエストの問題を受け付けています。コミュニティの参加は、改善の優先順位付けに役立ち、モデルがユーザーのニーズに合わせて進化することを保証します。
初心者は技術知識なしでこれを使用できますか?
Webデモは、即座に使用できるノーコードインターフェースを提供します。ローカルデプロイメントの場合、ComfyUIはコーディングなしでビジュアルワークフロービルディングを提供します。技術ユーザーは、プログラムによる制御のために完全なAPIにアクセスできます。
Qwenベースの画像モデルとの違いは何ですか?
Qwenがビジョン言語理解に焦点を当てているのに対し、このモデルは多言語テキストレンダリングと指示フォロー編集における独自の強みを持つ生成に特化しています。両方とも包括的なAIパイプラインで互いに補完できます。
バッチ処理はサポートされていますか?
はい。APIとComfyUIワークフローの両方が、複数のプロンプトを効率的に処理するためのバッチ生成をサポートしています。これは、高スループットを必要とする本番環境に役立ちます。
Z-Imageで創作を始めましょう
このオープンソース基盤モデルで効率的な生成を体験してください。無料でご利用いただけます。