from 52472+ happy users
Z-Image Turbo
Gratis Z-Image Turbo AI-beeldgenerator online, het 6B Z-Image AI-model van Tongyi-MAI. Maak en bewerk afbeeldingen met Z-Image Turbo en Z-Image-Edit.
Z-Image Turbo AI-beeldgenerator
Genereer en bewerk afbeeldingen met tekstprompts of afbeeldingen met Z-Image Turbo AI

Z-Image Inspiratiegalerij
Ontdek wat mogelijk is met de generatiemogelijkheden van Z-Image Turbo. Klik op een item om Z-Image-prompts te bekijken.






![[Art Style & Viewpoint]:
Hyper-realistic 8k product photography, macro lens perspective, strict 90-degree overhead flat-lay (knolling).
[Aesthetic Philosophy]: "Sublime Micro-Engineering Narratives". A blend of surgical precision and artistic interpretation of technical components.
[Subject Input]:
Target Object: Deconstructed Leica M3 Camera Body
[Action]: Forensic Technical Exploded View. Disassemble into 8-12 primary components, but with an emphasis on secondary and tertiary sub-components (e.g., individual gears within a gearbox, micro-switches on a circuit board, specific spring types, internal wiring harnesses).
[Detail Emphasis]: Each component is meticulously rendered.
Metals: Highlight brushed grains, polished edges, anodic oxidation sheen, laser-etched serial numbers or specific alloy markings. Show microscopic tolerances between parts.
Plastics: Reveal injection molding marks, precise seam lines, and subtle textural variations.
Circuitry: Emphasize the solder joints, traces, tiny capacitors, and integrated chip details.
Glass/Optics: Render reflections, anti-reflective coatings, and subtle refractions.
[Background]: Premium matte cool-grey workbench surface.
[Interactive Schematics]: Ultra-fine Cyan/Tech-Blue vector lines. Include cross-sectional views, exploded assembly sequence lines (dashed arrows), and material call-outs (e.g., "Alloy 7075", "Carbon Fiber Weave").
[Artistic Title Style]: "Industrial Stencil" Aesthetic. Large, bold, semi-transparent text (e.g., "PROJECT: ALPHA" or "ENGINE MODEL: X9") laser-etched onto the background surface.](https://pub-eb5b81bfee5c4e39ba2d1f7195360ef2.r2.dev/inspiration/7.jpeg)

















Vergelijking van verschillende modelresultaten
Bekijk hoe verschillende AI-modellen met dezelfde prompt uiteenlopende resultaten genereren.
Origineel beeld

Genereer bij Comiket een zeer gedetailleerde foto van een meisje dat deze illustratie cosplayt. Repliceer exact dezelfde pose, lichaamshouding, handgebaren, gezichtsuitdrukking en camerakader als in de originele illustratie. Houd dezelfde hoek, hetzelfde perspectief en dezelfde compositie aan, zonder enige afwijking
Generated Results

Flux Pro

Qwen

Seedream

Nano Banana













Modellen

Nano Banana Pro
NieuwNieuwste generatie met verbeterde kwaliteit
Nano Banana
UitgelichtUltrahoge karakterconsistentie

Seedream
NieuwOndersteunt afbeeldingen met samenhangende stijlen

Flux Dev
Voor korte en basisscènes

Qwen
NieuwGoed in het weergeven van complexe tekst
Flux Schnell Lora
NieuwSnelle, creatieve afbeeldingsgeneratie
Flux Kontext
Voor fotorealisme en creatieve controle
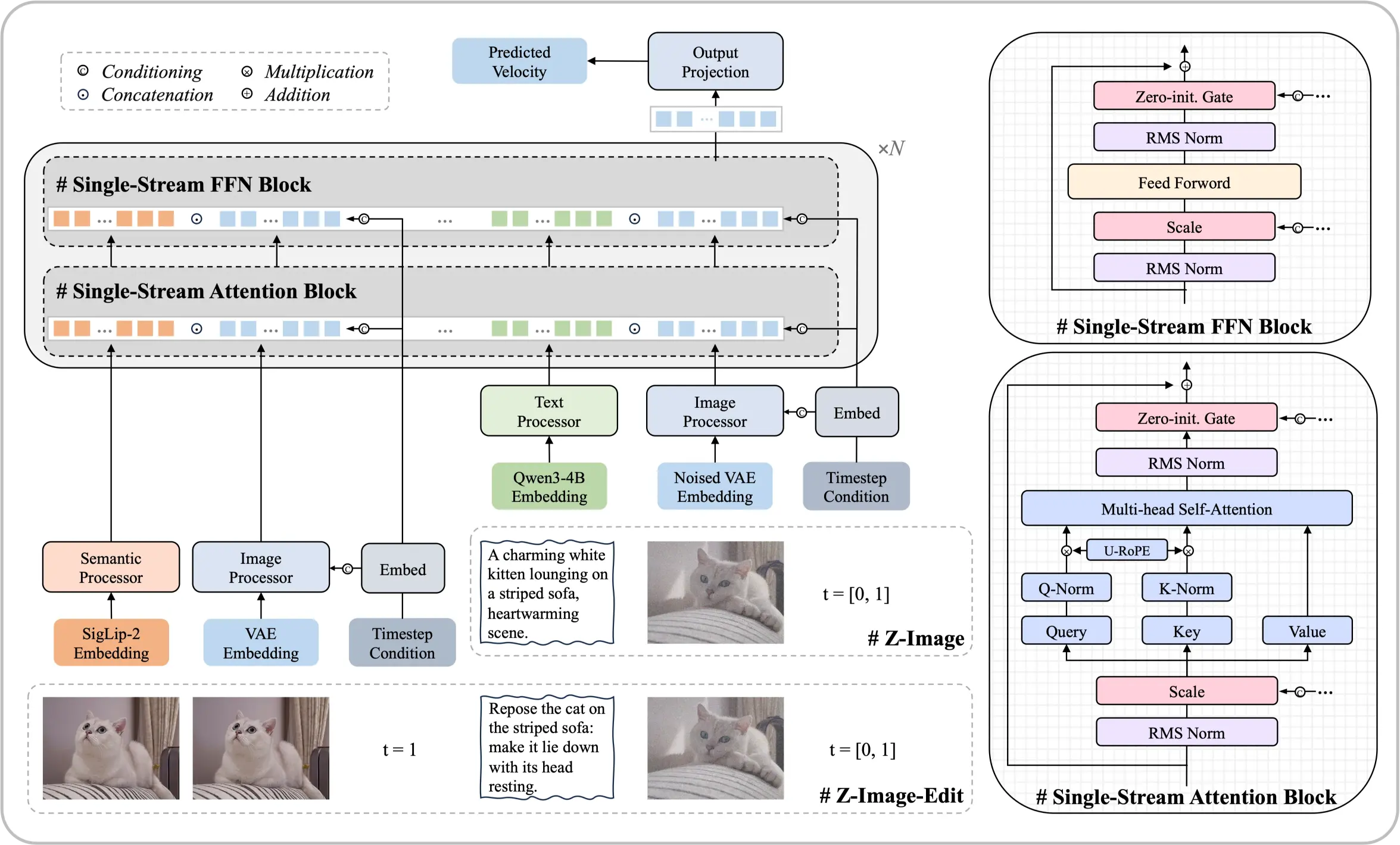
Maak kennis met het Z-Image Foundation-model
Een 6-miljard-parameter architectuur die bewijst dat eersteklas resultaten haalbaar zijn zonder enorme rekenbronnen. Dit open-source diffusiemodel levert fotorealistische outputs en tweetalige tekstweergave vergelijkbaar met toonaangevende commerciële oplossingen.
- Single-Stream ArchitectuurVerenigt tekstinsluitingen en latente verwerking in één efficiënte transformatorreeks.
- Fotografisch RealismePrecieze controle over belichting, texturen en details die aan professionele normen voldoen.
- Chinese & Engelse TekstNauwkeurige weergave van tweetalige tekst direct binnen gegenereerde beelden.
Kernsterktes van Dit Model
Systematische optimalisatie maakt prestaties mogelijk die concurreren met modellen een orde van grootte groter.
Aan de slag met Z-Image
Maak verbluffende afbeeldingen in vier eenvoudige stappen:
Wat Z-Image onderscheidt
Ontdek de mogelijkheden die Z-Image tot een leider onder de open-sourcealternatieven maken.
ComfyUI Integratie
Z-Image-nodes bieden native workflow-ondersteuning voor het naadloos opbouwen van pijplijnen.
Professionele Typografie
Sterke compositorische vaardigheden voor posterontwerp met nauwkeurige tekstplaatsing.
Instructies met Meerdere Stappen
Volgt complexe samengestelde prompts met logische samenhang.
Esthetisch Evenwicht
Beelden met hoge betrouwbaarheid en aangename compositie en sfeer.
Huggingface & ModelScope
Weights beschikbaar voor download op belangrijke modelrepositories.
GGUF & FP8 Formaten
Geoptimaliseerde gekwantiseerde versies voor efficiënte lokale implementatie.
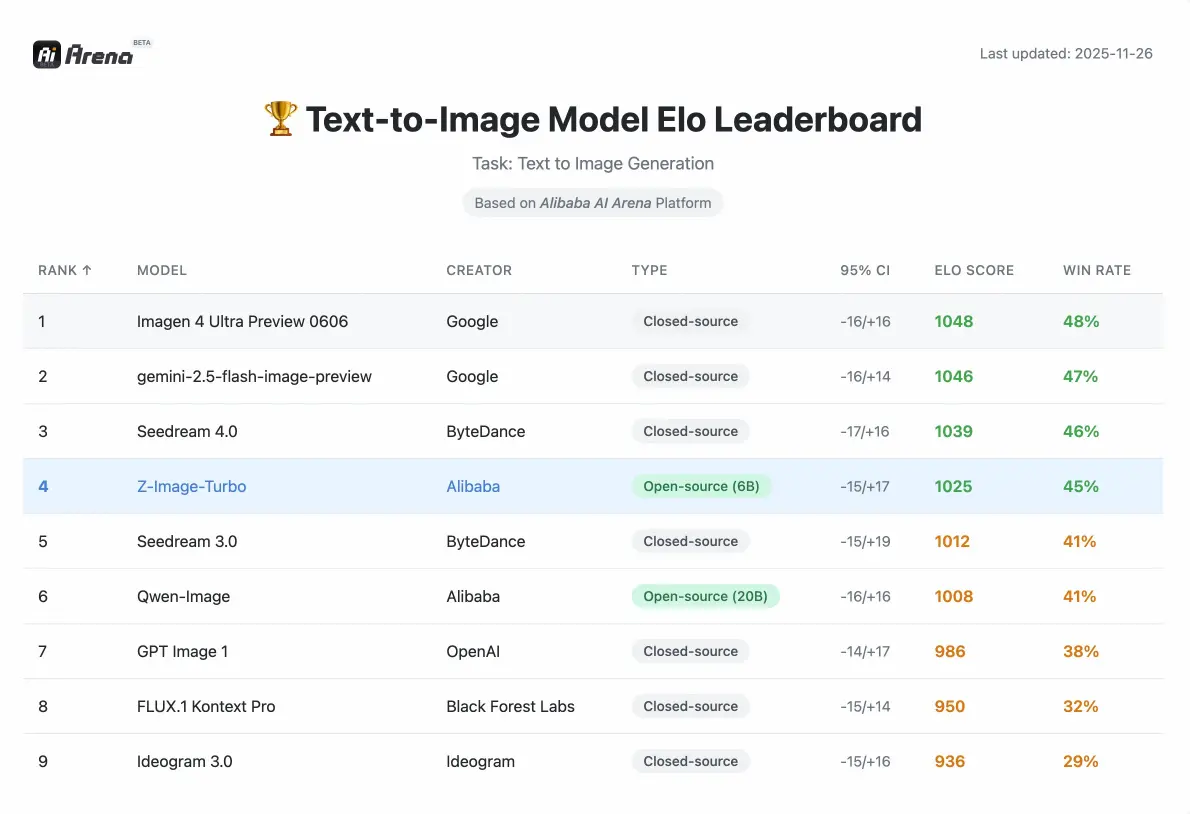
Z-Image-prestaties
Competitieve statistieken gevalideerd door menselijke voorkeursevaluaties op Alibaba AI Arena.
Parameters
6B
Compact Maar Krachtig
Stappen (Turbo)
8
Snelle Generatie
Vereist VRAM
<16GB
Consumentenhardware
Wat makers zeggen over Z-Image
Ervaringen van ontwerpers, ontwikkelaars en contentmakers die onze tools gebruiken.
David
Grafisch Ontwerper
De fotorealistische kwaliteit kan wedijveren met dure commerciële tools. Ik heb het binnen enkele minuten in mijn ComfyUI-pijplijn geïntegreerd.
Rachel
Contentmaker
Tweetalige tekstweergave is een gamechanger. Chinese karakters komen er helder uit zonder enige nabewerking.
Marcus
Ontwikkelaar
Ik heb de GGUF-versie gedownload van Huggingface en dezelfde middag lokaal laten draaien. Heel eenvoudig.
Sofia
Marketingdirecteur
De Edit-variant volgt complexe instructies nauwkeurig. Wij gebruiken het voor snelle aanpassingen van productfoto’s.
James
E-commerce
Het begrip van de scènecompositie is uitstekend. Productachtergronden zien er professioneel uit.
Anna
Kunstenaar
Culturele nauwkeurigheid heeft me onder de indruk gebracht. Het genereerde specifieke monumenten en traditionele elementen zonder hallucinaties.
Veelgestelde vragen over Z-Image
Alles wat u moet weten over Z-Image, ComfyUI-integratie en downloaden vanaf Huggingface.
Wat is Z-Image precies?
Z-Image is een efficiënt basismodel met 6 miljard parameters voor het genereren van beelden. Het is gebouwd op een Single-Stream Diffusion Transformer-architectuur en levert fotorealistische kwaliteit en tweetalige tekstweergave die vergelijkbaar is met toonaangevende commerciële oplossingen, zonder dat daarvoor enorme rekenkracht nodig is.
Hoe werkt de Single-Stream Diffusion-architectuur?
Deze architectuur verenigt de verwerking van tekstinbedding, voorwaardelijke invoer en latente ruis in één enkele reeks die in de transformatorbackbone wordt ingevoerd. Deze gestroomlijnde aanpak verbetert de efficiëntie terwijl de hoge uitvoerkwaliteit behouden blijft, waardoor het model op consumentenhardware kan draaien.
Wat is Z-Image-Turbo?
Z-Image-Turbo is een gedistilleerde variant die is geoptimaliseerd voor snelheid. Het realiseert een fotorealistische generatie met nauwkeurige tweetalige tekstweergave in slechts 8 inferentiestappen, waardoor resultaten worden geleverd die vergelijkbaar zijn met of beter zijn dan die van concurrenten die veel meer stappen vereisen.
Wat is Z-Image-Edit?
Z-Image-Edit is een variant voor voortgezette training, gespecialiseerd in het aanpassen van bestaande beelden. Het blinkt uit in het volgen van complexe instructies voor taken variërend van nauwkeurige lokale aanpassingen tot globale stijltransformaties, terwijl de consistentie van de bewerkingen behouden blijft.
Kan ik dit gebruiken met ComfyUI?
Ja. Het model integreert van nature met ComfyUI via aangepaste nodes. Je kunt complexe workflows bouwen die generatie, bewerking en nabewerking combineren, allemaal binnen de ComfyUI-interface. Door de gemeenschap gemaakte workflow-templates zijn beschikbaar om je snel op weg te helpen.
Waar kan ik de weights downloaden?
Modelgewichten zijn beschikbaar op zowel Huggingface als ModelScope. Afhankelijk van uw gebruiksscenario kunt u het basismodel, de Turbo-variant of de Edit-variant downloaden. Er zijn ook GGUF- en FP8-gekwantiseerde versies beschikbaar voor efficiënte lokale implementatie.
Welke hardware heb ik nodig om het lokaal uit te voeren?
Het model draait soepel op consumentenvideok aarten met minder dan 16GB VRAM. Dit maakt geavanceerde generatietechnologie toegankelijk zonder dure professionele hardware. De gekwantiseerde GGUF- en FP8-versies verminderen geheugenvereisten verder.
Ondersteunt het Chinese tekst in gegenereerde beelden?
Ja. Het model heeft uitstekende tweetalige weergavemogelijkheden voor zowel Chinese als Engelse tekst. Het kan tekst nauwkeurig binnen beelden plaatsen met behoud van esthetische compositie en leesbaarheid, zelfs bij kleinere lettergroottes.
Hoe vergelijkt de prestatie met andere open-source modellen?
Volgens de op Elo gebaseerde Human Preference Evaluation on the Alibaba AI Arena vertoont dit model zeer competitieve prestaties ten opzichte van toonaangevende alternatieven en behaalt het state-of-the-art resultaten onder open-sourceopties in zijn parameterklasse.
Wat is de Prompt Enhancer?
De Prompt Enhancer (PE) gebruikt een gestructureerde redeneerketen om logica en gezond verstand in het generatieproces te injecteren. Dit maakt het mogelijk om complexe taken uit te voeren, zoals het kip-en-konijnprobleem of het visualiseren van klassieke poëzie met logische samenhang.
Is het model echt open source?
Ja. De code, gewichten en een online demo zijn openbaar beschikbaar. Het doel is het bevorderen van de ontwikkeling van toegankelijke, goedkope en krachtige generatieve modellen waarvan de gehele onderzoeks- en ontwikkelaarsgemeenschap profiteert.
Kan het omgaan met complexe instructies met meerdere delen?
Vooral de Edit-variant blinkt hier uit. Het kan samengestelde instructies uitvoeren, zoals het gelijktijdig wijzigen van de uitdrukking en houding van een personage en tegelijkertijd specifieke tekst toevoegen, waardoor de consistentie bij alle wijzigingen behouden blijft.
Hoe wordt cultureel begrip geïmplementeerd?
Het model beschikt over uitgebreide kennis van wereldoriëntatiepunten, historische figuren, culturele concepten en specifieke objecten uit de echte wereld. Dit maakt een nauwkeurige generatie van diverse onderwerpen mogelijk zonder hallucinaties of culturele onnauwkeurigheden.
Wat maakt de tekstweergave speciaal?
Naast tweetalige ondersteuning toont het model sterke typografische vaardigheden voor posterontwerp en complexe composities. Het kan uitdagende scenario's aan, zoals kleine lettergroottes of ingewikkelde lay-outs, terwijl de tekstprecisie en visuele aantrekkingskracht behouden blijven.
Hoe integreer ik het in mijn bestaande pijplijn?
Voor ComfyUI-gebruikers, download gewoon de aangepaste nodes en laad de weights. Voor programmatische toegang volgt het model standaard diffusie-model API's. Documentatie bevat voorbeeldcode voor Python-integratie, API-endpoints en workflow-templates.
Hoe zit het met de FP8- en GGUF-versies?
Dit zijn gekwantiseerde versies geoptimaliseerd voor efficiënte implementatie. FP8 behoudt hoge kwaliteit met verminderde precisie, terwijl GGUF maximale compatibiliteit biedt voor lokale inferentie. Beide verminderen VRAM-vereisten onder het basismodel.
Kan ik het gebruiken voor commerciële projecten?
Het model is vrijgegeven als open source met een permissieve licentie. Controleer de specifieke licentiegegevens op de repositorypagina voor richtlijnen voor commercieel gebruik. De meeste standaard commerciële toepassingen zijn toegestaan.
Hoe vergelijkt het met Stable Diffusion?
Hoewel beide op diffusie gebaseerd zijn, gebruikt dit model een aparte Single-Stream-architectuur die de verwerking verenigt. Het blinkt vooral uit in tweetalige tekstweergave en het volgen van instructies, gebieden waar standaard Stable Diffusion-modellen vaak moeite mee hebben.
Welke resolutie ondersteunt het?
Het basismodel ondersteunt standaardresoluties geoptimaliseerd voor kwaliteits- en snelheidsbalans. Hogere resoluties zijn haalbaar via de ComfyUI-workflow met geschikte upscaling-nodes. Controleer de documentatie voor aanbevolen resolutie-instellingen.
Is er een API beschikbaar?
Ja. Er wordt zowel een webdemo als programmatische API-toegang geboden. U kunt generatiemogelijkheden rechtstreeks in uw applicaties integreren zonder de lokale infrastructuur te hoeven beheren, indien gewenst.
Hoe vaak wordt het model bijgewerkt?
Het ontwikkelteam onderhoudt en verbetert het model actief. Updates omvatten prestatieoptimalisaties, uitgebreide mogelijkheden en door de gemeenschap gevraagde functies. Volg de repository voor aankondigingen.
Kan het gezichten nauwkeurig genereren?
Het model produceert zeer realistische gelaatstrekken met fijne controle over uitdrukkingen en details. Gecombineerd met nauwkeurige tekstoverlay-mogelijkheden is het bijzonder geschikt voor portretgebaseerde inhoud en marketingmateriaal.
Hoe zit het met stijloverdracht en artistieke effecten?
De variant Bewerken verwerkt stijltransformaties terwijl de identiteit van het onderwerp behouden blijft. U kunt artistieke effecten toepassen, achtergronden veranderen of de esthetiek aanpassen terwijl de consistentie in de visuele kernelementen behouden blijft.
Hoe werken LoRA-aanpassingen met dit model?
Aangepaste LoRA-gewichten kunnen worden getraind en toegepast om het model te specialiseren voor bepaalde stijlen of onderwerpen. De architectuur ondersteunt standaard LoRA-integratiemethoden die bekend zijn bij gebruikers van andere diffusiemodellen.
Wat maakt het efficiënt vergeleken met grotere modellen?
Systematische optimalisatie op architectuurniveau maakt het mogelijk dat 6B-parameters outputs evenaren van modellen die 10x groter zijn. Deze efficiëntie vertaalt zich naar snellere inferentie, lagere hardwarevereisten en verminderde operationele kosten.
Is er gemeenschapsondersteuning beschikbaar?
Ja. Actieve gemeenschappen bestaan op Discord, GitHub en forums waar gebruikers workflows delen, problemen oplossen en creaties tentoonstellen. Het ontwikkelteam communiceert regelmatig met gemeenschapsfeedback.
Hoe rapporteer ik bugs of vraag ik functies aan?
De GitHub-repository accepteert issues voor bugrapporten en functieverzoeken. Deelname van de gemeenschap helpt bij het prioriteren van verbeteringen en zorgt ervoor dat het model evolueert om aan gebruikersbehoeften te voldoen.
Kunnen beginners dit gebruiken zonder technische kennis?
De webdemo biedt een no-code-interface voor onmiddellijk gebruik. Voor lokale implementatie biedt ComfyUI visuele workflow-building zonder coderen. Technische gebruikers kunnen de volledige API benaderen voor programmatische controle.
Wat onderscheidt dit van Qwen-gebaseerde afbeeldingsmodellen?
Terwijl Qwen zich richt op het begrijpen van visie-taal, is dit model gespecialiseerd in het genereren van teksten met unieke sterke punten op het gebied van tweetalige tekstweergave en instructie-volgende bewerking. Beide kunnen elkaar aanvullen in uitgebreide AI-pijplijnen.
Wordt batchverwerking ondersteund?
Ja. Zowel de API- als de ComfyUI-workflows ondersteunen batchgeneratie voor het efficiënt verwerken van meerdere prompts. Dit is handig voor productieomgevingen die een hoge doorvoer vereisen.
Begin met creëren met Z-Image
Ervaar efficiënte generatie met dit open-source foundation model. Gratis te gebruiken.