from 52472+ happy users
Imagem Z Turbo
Gerador de Imagens IA Z-Image Turbo Gratuito Online, o modelo de IA de imagem 6B Z da Tongyi-MAI. Crie e edite imagens com Z-Image Turbo e Z-Image-Edit.
Gerador de imagem Z-Image Turbo AI
Gere e edite imagens com prompts de texto ou imagens por Z-Image Turbo AI

Galeria de inspiração Z-Image
Explore o que é possível com os recursos de geração Z-Image Turbo. Clique em qualquer item para visualizar os prompts do Z-Image.






![[Art Style & Viewpoint]:
Hyper-realistic 8k product photography, macro lens perspective, strict 90-degree overhead flat-lay (knolling).
[Aesthetic Philosophy]: "Sublime Micro-Engineering Narratives". A blend of surgical precision and artistic interpretation of technical components.
[Subject Input]:
Target Object: Deconstructed Leica M3 Camera Body
[Action]: Forensic Technical Exploded View. Disassemble into 8-12 primary components, but with an emphasis on secondary and tertiary sub-components (e.g., individual gears within a gearbox, micro-switches on a circuit board, specific spring types, internal wiring harnesses).
[Detail Emphasis]: Each component is meticulously rendered.
Metals: Highlight brushed grains, polished edges, anodic oxidation sheen, laser-etched serial numbers or specific alloy markings. Show microscopic tolerances between parts.
Plastics: Reveal injection molding marks, precise seam lines, and subtle textural variations.
Circuitry: Emphasize the solder joints, traces, tiny capacitors, and integrated chip details.
Glass/Optics: Render reflections, anti-reflective coatings, and subtle refractions.
[Background]: Premium matte cool-grey workbench surface.
[Interactive Schematics]: Ultra-fine Cyan/Tech-Blue vector lines. Include cross-sectional views, exploded assembly sequence lines (dashed arrows), and material call-outs (e.g., "Alloy 7075", "Carbon Fiber Weave").
[Artistic Title Style]: "Industrial Stencil" Aesthetic. Large, bold, semi-transparent text (e.g., "PROJECT: ALPHA" or "ENGINE MODEL: X9") laser-etched onto the background surface.](https://pub-eb5b81bfee5c4e39ba2d1f7195360ef2.r2.dev/inspiration/7.jpeg)













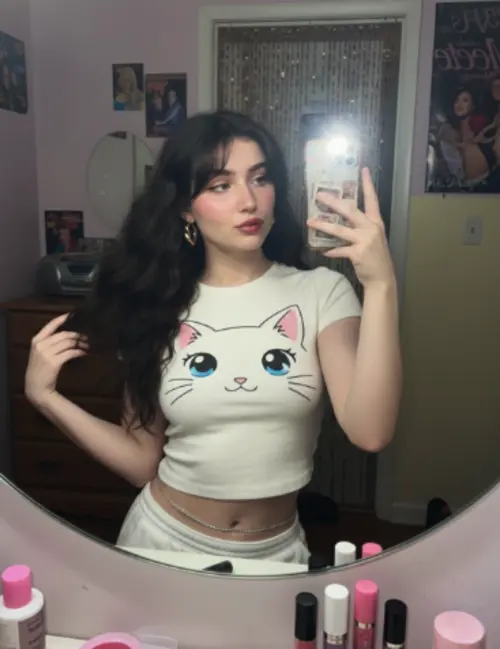




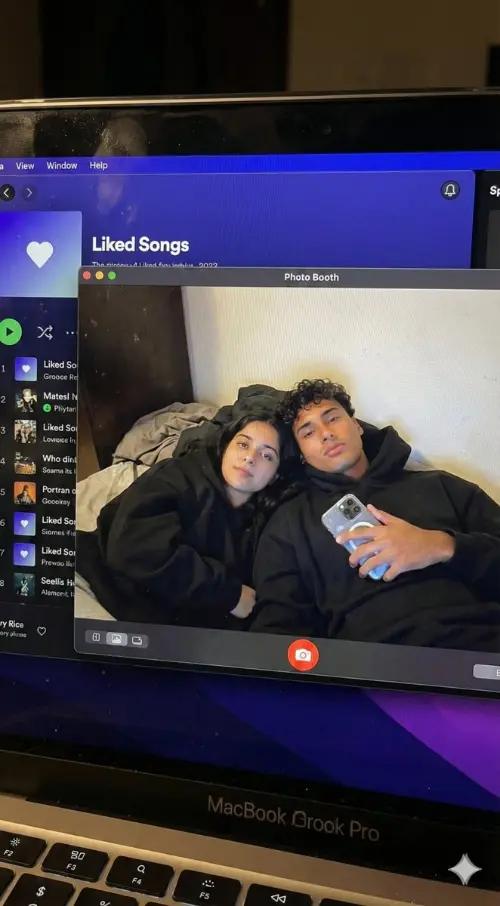
Comparação de diferentes resultados de modelos
Veja como diferentes modelos de IA geram resultados variados com o mesmo prompt.
Imagem original

Gere uma foto altamente detalhada de uma garota fazendo cosplay desta ilustração, no Comiket. Replique exatamente a mesma pose, postura corporal, gestos com as mãos, expressão facial e enquadramento da câmera da ilustração original. Mantenha o mesmo ângulo, perspectiva e composição, sem qualquer desvio
Generated Results

Flux Pro

Qwen

Seedream

Nano Banana













Modelos

Nano Banana Pro
NovoÚltima geração com qualidade aprimorada
Nano Banana
DestaqueConsistência ultra-alta de personagens

Seedream
NovoSuporta imagens com estilos coesos

Flux Dev
Para cenas curtas e básicas

Qwen
NovoExcelente em renderização de texto complexo
Flux Schnell Lora
NovoGeração rápida e criativa de imagens
Flux Kontext
Para fotorrealismo e controle criativo
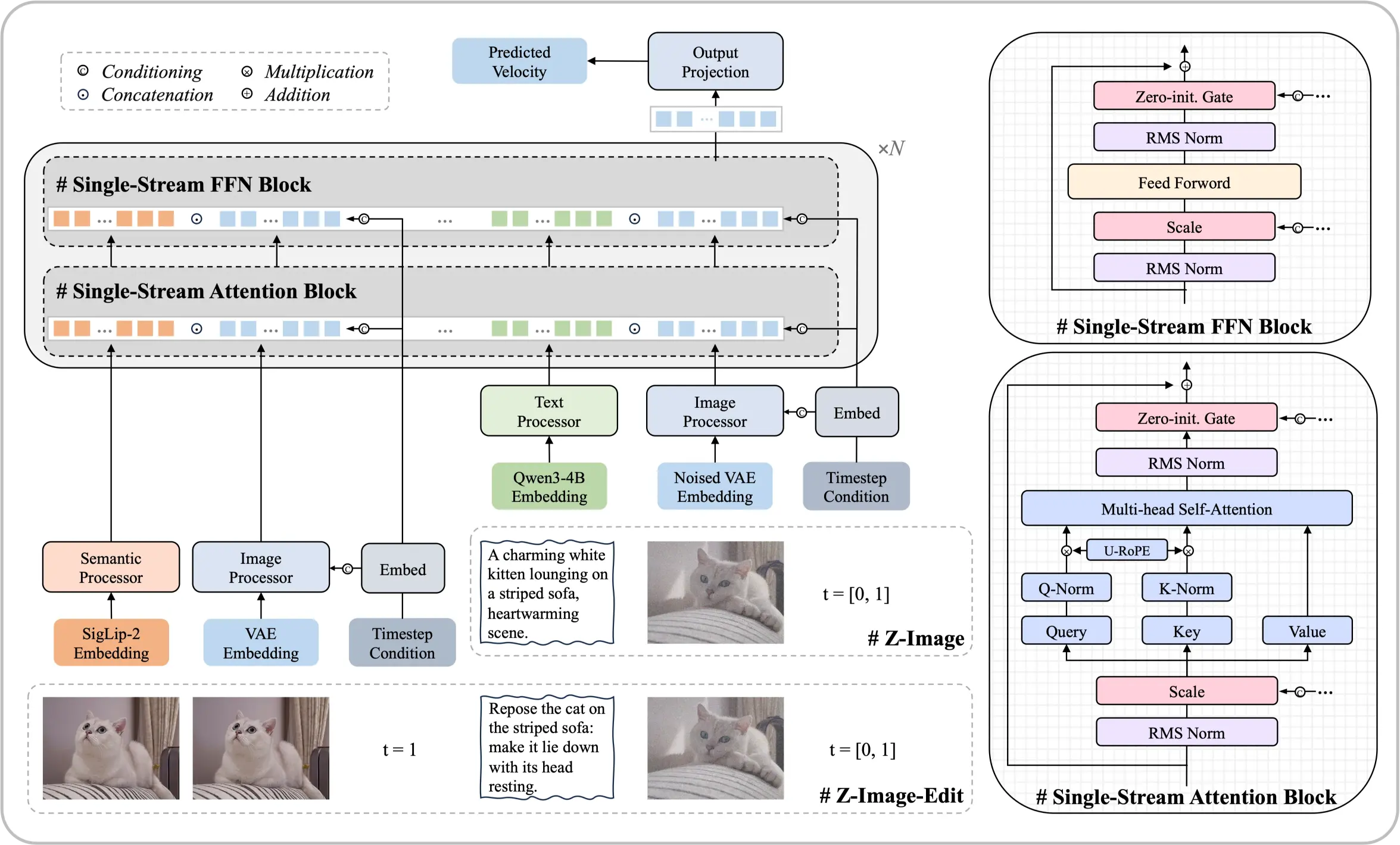
Conheça o modelo Z-Image Foundation
Uma arquitetura de 6 bilhões de parâmetros que comprova que resultados de nível superior são alcançáveis sem recursos computacionais massivos. Este modelo de difusão de código aberto entrega saídas fotorrealistas e renderização de texto bilíngue comparável às principais soluções comerciais.
- Arquitetura de Fluxo ÚnicoUnifica incorporações de texto e processamento latente em uma sequência transformadora eficiente.
- Realismo de Nível FotográficoControle preciso sobre iluminação, texturas e detalhes que atingem padrões profissionais.
- Texto em Chinês e InglêsRenderização precisa de texto bilíngue diretamente dentro dos visuais gerados.
Principais Pontos Fortes Deste Modelo
Otimização sistemática permite desempenho que rivaliza com modelos uma ordem de magnitude maiores.
Primeiros passos com imagem Z
Crie visuais impressionantes em quatro etapas simples:
O que diferencia a Z-Image
Explore os recursos que tornam o Z-Image um líder entre as alternativas de código aberto.
Integração ComfyUI
Os nós Z-Image fornecem suporte de fluxo de trabalho nativo para construção contínua de pipeline.
Tipografia Profissional
Fortes habilidades composicionais para design de pôster com posicionamento preciso de texto.
Instruções de Várias Etapas
Segue prompts compostos complexos com coerência lógica.
Equilíbrio Estético
Visuais de alta fidelidade com composição agradável e atmosfera.
Huggingface e ModelScope
Pesos disponíveis para download nos principais repositórios de modelos.
Formatos GGUF e FP8
Versões quantizadas otimizadas para implantação local eficiente.
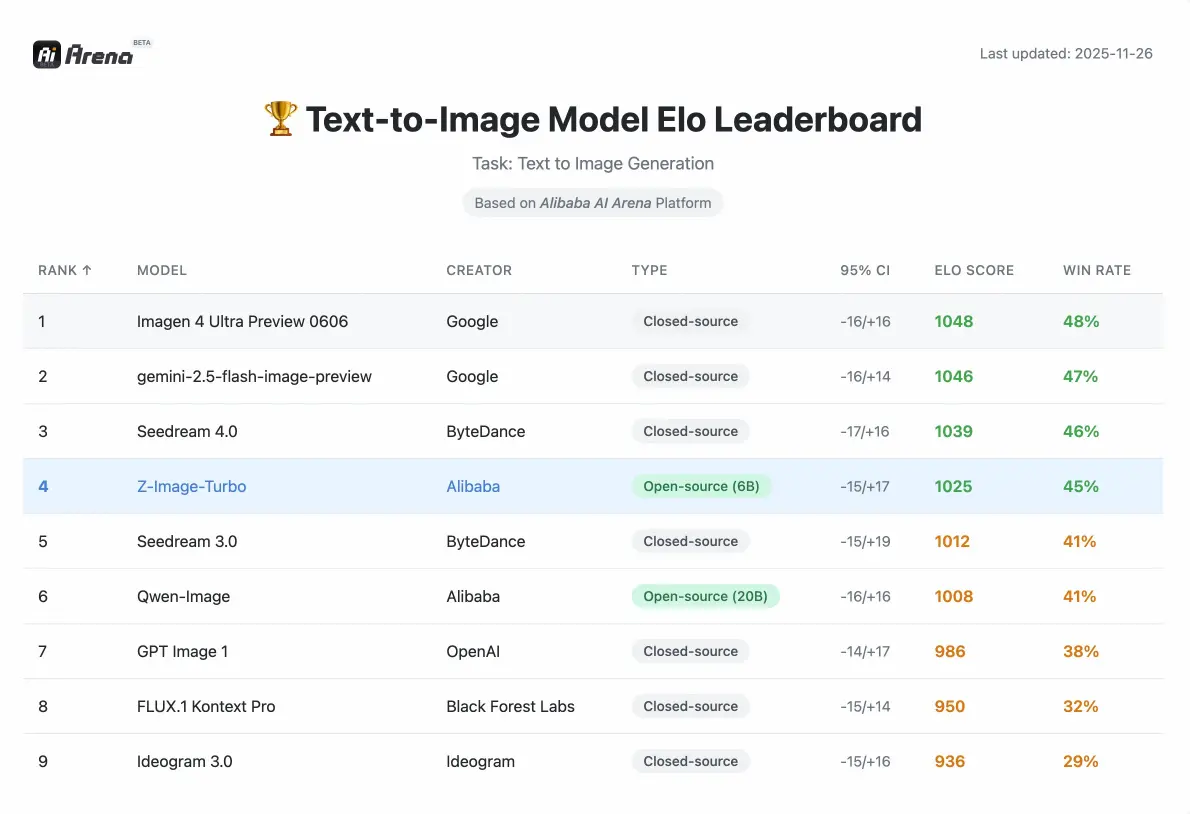
Desempenho da imagem Z
Métricas competitivas validadas por avaliações de preferências humanas na Alibaba AI Arena.
Parâmetros
6B
Compacto mas Poderoso
Etapas (Turbo)
8
Geração Rápida
VRAM Necessária
<16GB
Hardware Consumidor
O que os criadores dizem sobre Z-Image
Experiências de designers, desenvolvedores e criadores de conteúdo que utilizam nossas ferramentas.
David
Designer Gráfico
A qualidade fotorrealista rivaliza com ferramentas comerciais caras. Integrei ao meu pipeline ComfyUI em minutos.
Rachel
Criadora de Conteúdo
A renderização de texto bilíngue é revolucionária. Caracteres chineses saem nítidos sem pós-processamento.
Marcus
Desenvolvedor
Baixei a versão GGUF do Huggingface e coloquei-a rodando localmente na mesma tarde. Muito simples.
Sofia
Diretora de Marketing
A variante Editar segue instruções complexas com precisão. Nós o usamos para ajustes rápidos nas fotos do produto.
James
E-commerce
A compreensão da composição de cena é excelente. Fundos de produtos parecem fotografados profissionalmente.
Anna
Artista
A precisão cultural me impressionou. Gerou marcos específicos e elementos tradicionais sem alucinações.
Perguntas frequentes sobre imagem Z
Tudo o que você precisa saber sobre Z-Image, integração ComfyUI e download do Huggingface.
O que exatamente é Z-Image?
Z-Image é um modelo básico eficiente de 6 bilhões de parâmetros para geração de recursos visuais. Construído em uma arquitetura Single-Stream Diffusion Transformer, ele oferece qualidade fotorrealista e renderização de texto bilíngue comparável às principais soluções comerciais, sem exigir enormes recursos computacionais.
Como funciona a arquitetura Single-Stream Diffusion?
Essa arquitetura unifica o processamento de incorporações de texto, entradas condicionais e latentes ruidosas em uma única sequência alimentada no backbone do transformador. Essa abordagem simplificada melhora a eficiência enquanto mantém a alta qualidade de saída, permitindo que o modelo seja executado em hardware de consumo.
O que é Z-Image-Turbo?
Z-Image-Turbo é uma variante destilada otimizada para velocidade. Ele alcança geração fotorrealista com renderização precisa de texto bilíngue em apenas 8 etapas de inferência, fornecendo resultados comparáveis ou superiores aos concorrentes que exigem muito mais etapas.
O que é Z-Image-Edit?
Z-Image-Edit é uma variante de treinamento contínuo especializada para modificar visuais existentes. Ele é excelente em seguir instruções complexas para tarefas que vão desde ajustes locais precisos até transformações globais de estilo, mantendo a consistência da edição.
Posso usar isso com ComfyUI?
Sim. O modelo integra nativamente com ComfyUI através de nós personalizados. Você pode construir fluxos de trabalho complexos combinando geração, edição e pós-processamento, tudo dentro da interface ComfyUI. Modelos de fluxo de trabalho criados pela comunidade estão disponíveis para ajudá-lo a começar rapidamente.
Onde posso baixar os pesos?
Os pesos dos modelos estão disponíveis no Huggingface e no ModelScope. Você pode baixar o modelo básico, a variante Turbo ou a variante Editar, dependendo do seu caso de uso. Versões quantizadas GGUF e FP8 também são fornecidas para implantação local eficiente.
Qual hardware eu preciso para rodar localmente?
O modelo funciona perfeitamente em placas gráficas de consumo com menos de 16 GB de VRAM. Isso torna a tecnologia de geração avançada acessível sem a necessidade de hardware profissional caro. As versões quantizadas GGUF e FP8 reduzem ainda mais os requisitos de memória.
Ele suporta texto chinês em visuais gerados?
Sim. O modelo tem excelentes capacidades de renderização bilíngue para texto chinês e inglês. Pode colocar texto com precisão dentro dos visuais mantendo composição estética e legibilidade, mesmo em tamanhos de fonte menores.
Como o desempenho se compara a outros modelos de código aberto?
De acordo com a Avaliação de Preferência Humana baseada em Elo no Alibaba AI Arena, este modelo mostra desempenho altamente competitivo em relação às principais alternativas e alcança resultados de última geração entre as opções de código aberto em sua classe de parâmetros.
O que é o Prompt Enhancer?
O Prompt Enhancer (PE) usa uma cadeia de raciocínio estruturada para injetar lógica e bom senso no processo de geração. Isso permite lidar com tarefas complexas como o problema da galinha e do coelho ou visualizar poesia clássica com coerência lógica.
O modelo é realmente de código aberto?
Sim. O código, os pesos e uma demonstração online estão disponíveis publicamente. O objetivo é promover o desenvolvimento de modelos generativos acessíveis, de baixo custo e de alto desempenho que beneficiem toda a comunidade de pesquisa e desenvolvimento.
Ele pode lidar com instruções complexas de várias partes?
A variante Editar se destaca particularmente aqui. Ele pode executar instruções compostas, como modificar simultaneamente a expressão e a pose de um personagem enquanto adiciona um texto específico, mantendo a consistência em todas as alterações.
Como a compreensão cultural é implementada?
O modelo possui vasto conhecimento de marcos mundiais, figuras históricas, conceitos culturais e objetos específicos do mundo real. Isso permite a geração precisa de diversos assuntos sem alucinações ou imprecisões culturais.
O que torna a renderização de texto especial?
Além do suporte bilíngue, o modelo demonstra fortes habilidades tipográficas para design de pôsteres e composições complexas. Ele lida com cenários desafiadores, como tamanhos de fonte pequenos ou layouts complexos, mantendo a precisão textual e o apelo visual.
Como eu integro isso ao meu pipeline existente?
Para usuários ComfyUI, simplesmente baixe os nós personalizados e carregue os pesos. Para acesso programático, o modelo segue APIs padrão de modelo de difusão. A documentação inclui código de exemplo para integração Python, endpoints de API e modelos de fluxo de trabalho.
E as versões FP8 e GGUF?
Estas são versões quantizadas otimizadas para implantação eficiente. O FP8 mantém alta qualidade com precisão reduzida, enquanto o GGUF fornece compatibilidade máxima para inferência local. Ambos reduzem os requisitos de VRAM abaixo do modelo básico.
Posso usar para projetos comerciais?
O modelo é lançado como código aberto com uma licença permissiva. Verifique os detalhes específicos da licença na página do repositório para obter diretrizes de uso comercial. A maioria das aplicações comerciais padrão são permitidas.
Como se compara ao Stable Diffusion?
Embora ambos sejam baseados em difusão, este modelo usa uma arquitetura Single-Stream distinta que unifica o processamento. Particularmente se destaca em renderização de texto bilíngue e seguimento de instruções, áreas onde os modelos padrão Stable Diffusion frequentemente têm dificuldades.
Qual resolução ele suporta?
O modelo básico suporta resoluções padrão otimizadas para equilíbrio de qualidade e velocidade. Resoluções mais altas são possíveis por meio do fluxo de trabalho ComfyUI com nós de upscaling apropriados. Verifique a documentação para obter as configurações de resolução recomendadas.
Há uma API disponível?
Sim. Tanto uma demonstração web quanto acesso programático à API são fornecidos. Você pode integrar capacidades de geração diretamente em suas aplicações sem gerenciar infraestrutura local, se preferir.
Com que frequência o modelo é atualizado?
A equipe de desenvolvimento mantém e melhora ativamente o modelo. As atualizações incluem otimizações de desempenho, recursos expandidos e recursos solicitados pela comunidade. Siga o repositório para anúncios.
Ele pode gerar rostos com precisão?
O modelo produz características faciais altamente realistas com controle fino sobre expressões e detalhes. Combinado com capacidades precisas de sobreposição de texto, é particularmente adequado para conteúdo baseado em retratos e materiais de marketing.
E quanto à transferência de estilo e efeitos artísticos?
A variante Editar lida com transformações de estilo enquanto preserva a identidade do assunto. Você pode aplicar efeitos artísticos, alterar planos de fundo ou modificar a estética enquanto mantém a consistência nos principais elementos visuais.
Como funcionam as adaptações LoRA com este modelo?
Pesos LoRA personalizados podem ser treinados e aplicados para especializar o modelo em estilos ou assuntos específicos. A arquitetura suporta métodos padrão de integração LoRA familiares aos usuários de outros modelos de difusão.
O que o torna eficiente comparado a modelos maiores?
Otimização sistemática em nível de arquitetura permite que 6B parâmetros correspondam a saídas de modelos 10x maiores. Esta eficiência se traduz em inferência mais rápida, requisitos de hardware menores e custos operacionais reduzidos.
O suporte da comunidade está disponível?
Sim. Comunidades ativas existem no Discord, GitHub e fóruns onde usuários compartilham fluxos de trabalho, solucionam problemas e mostram criações. A equipe de desenvolvimento se envolve regularmente com feedback da comunidade.
Como eu reporto bugs ou solicito recursos?
O repositório GitHub aceita issues para relatórios de bugs e solicitações de recursos. A participação da comunidade ajuda a priorizar melhorias e garante que o modelo evolua para atender às necessidades dos usuários.
Iniciantes podem usar isso sem conhecimento técnico?
A demonstração web fornece uma interface sem código para uso imediato. Para implantação local, o ComfyUI oferece construção visual de fluxo de trabalho sem codificação. Usuários técnicos podem acessar a API completa para controle programático.
O que distingue isso dos modelos de imagem baseados em Qwen?
Embora Qwen se concentre na compreensão da linguagem visual, este modelo é especializado na geração com pontos fortes únicos na renderização de texto bilíngue e na edição de acompanhamento de instruções. Ambos podem complementar-se em pipelines abrangentes de IA.
O processamento em lote é suportado?
Sim. Tanto a API quanto os fluxos de trabalho ComfyUI suportam geração em lote para processar múltiplos prompts eficientemente. Isso é útil para ambientes de produção que exigem alto throughput.
Comece a criar com Z-Image
Experimente geração eficiente com este modelo fundamental de código aberto. Gratuito para uso.