from 52472+ happy users
Z-Image Turbo
Gratis Z-Image Turbo AI-bildgenerator online, 6B Z-Image AI-modellen av Tongyi-MAI. Skapa och redigera bilder med Z-Image Turbo och Z-Image-Edit.
Z-Image Turbo AI bildgenerator
Generera och redigera bilder med textmeddelanden eller bilder av Z-Image Turbo AI

Z-Image Inspiration Gallery
Utforska vad som är möjligt med Z-Image Turbo-genereringsmöjligheter. Klicka på ett objekt för att se Z-Image-meddelanden.






![[Art Style & Viewpoint]:
Hyper-realistic 8k product photography, macro lens perspective, strict 90-degree overhead flat-lay (knolling).
[Aesthetic Philosophy]: "Sublime Micro-Engineering Narratives". A blend of surgical precision and artistic interpretation of technical components.
[Subject Input]:
Target Object: Deconstructed Leica M3 Camera Body
[Action]: Forensic Technical Exploded View. Disassemble into 8-12 primary components, but with an emphasis on secondary and tertiary sub-components (e.g., individual gears within a gearbox, micro-switches on a circuit board, specific spring types, internal wiring harnesses).
[Detail Emphasis]: Each component is meticulously rendered.
Metals: Highlight brushed grains, polished edges, anodic oxidation sheen, laser-etched serial numbers or specific alloy markings. Show microscopic tolerances between parts.
Plastics: Reveal injection molding marks, precise seam lines, and subtle textural variations.
Circuitry: Emphasize the solder joints, traces, tiny capacitors, and integrated chip details.
Glass/Optics: Render reflections, anti-reflective coatings, and subtle refractions.
[Background]: Premium matte cool-grey workbench surface.
[Interactive Schematics]: Ultra-fine Cyan/Tech-Blue vector lines. Include cross-sectional views, exploded assembly sequence lines (dashed arrows), and material call-outs (e.g., "Alloy 7075", "Carbon Fiber Weave").
[Artistic Title Style]: "Industrial Stencil" Aesthetic. Large, bold, semi-transparent text (e.g., "PROJECT: ALPHA" or "ENGINE MODEL: X9") laser-etched onto the background surface.](https://pub-eb5b81bfee5c4e39ba2d1f7195360ef2.r2.dev/inspiration/7.jpeg)

















Jämförelse av olika modellresultat
Se hur olika AI-modeller genererar olika resultat med samma prompt.
Originalbild

Skapa ett mycket detaljerat foto av en tjej som cosplayer den här illustrationen, på Comiket. Exakt samma pose, kroppsställning, handgester, ansiktsuttryck och kamerainramning som i originalillustrationen. Behåll samma vinkel, perspektiv och komposition, utan någon avvikelse
Genererad Results

Flux Pro

Qwen

Seedream

Nano Banana













Modeller

Nano Banana Pro
NySenaste generationen med förbättrad kvalitet
Nano Banana
UtvaldUltrahög karaktärskonsistens

Seedream
NyStödjer bilder med sammanhållna stilar

Flux Dev
För korta och enkla scener

Qwen
NyBra på komplex textrendering
Flux Schnell Lora
NySnabb, kreativ bildgenerering
Flux Kontext
För fotorealism och kreativ kontroll
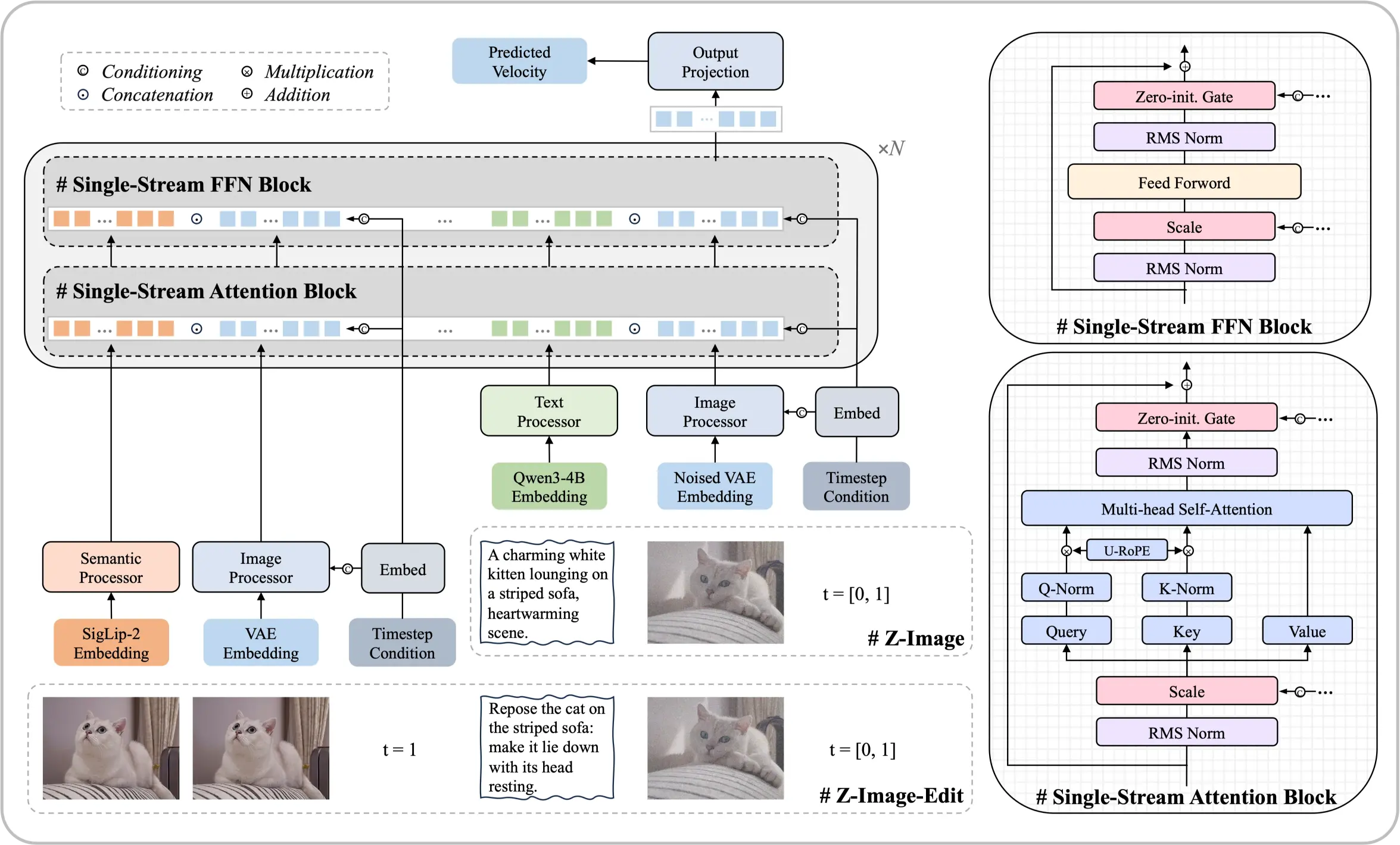
Möt Z-Image Foundation Model
En 6-miljarders parameterarkitektur som bevisar att toppresultat är möjliga utan massiva beräkningsresurser. Denna diffusionsmodell med öppen källkod levererar fotorealistiska resultat och tvåspråkig textrendering jämförbar med ledande kommersiella lösningar.
- EnkelströmsarkitekturFörenar textinbäddningar och latent bearbetning i en effektiv transformersekvens.
- Fotografi-nivå realismFin kontroll över belysning, texturer och detaljer som matchar professionella standarder.
- Kinesisk och engelsk textNoggrann rendering av tvåspråkig text direkt i genererade bilder.
Modellens kärnstyrkor
Systematisk optimering möjliggör prestanda som konkurrerar med modeller en storleksordning större.
Komma igång med Z-Image
Skapa fantastiska bilder i fyra enkla steg:
Det som skiljer Z-Image åt
Utforska funktionerna som gör Z-Image till en ledare bland alternativ med öppen källkod.
ComfyUI-integration
Z-Image-noder ger inbyggt arbetsflödesstöd för sömlös pipelinebyggande.
Professionell typografi
Starka kompositionsförmågor för affischdesign med exakt textplacering.
Flerstegs instruktioner
Följer komplexa sammansatta prompter med logisk koherens.
Estetisk balans
Högkvalitativa bilder med tilltalande komposition och stämning.
Huggingface och ModelScope
Vikter tillgängliga för nedladdning på stora modellarkiv.
GGUF- och FP8-format
Optimerade kvantiserade versioner för effektiv lokal distribution.
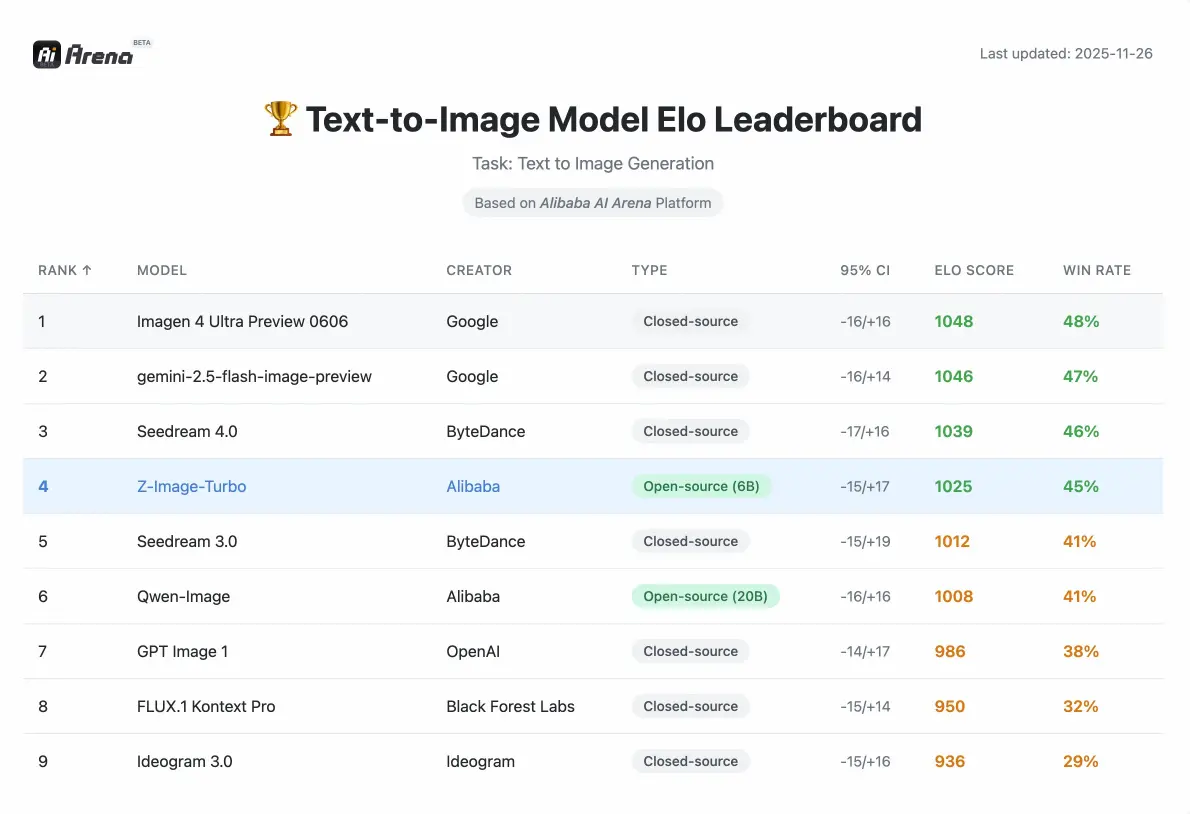
Z-Image Performance
Konkurrensmätningar validerade av utvärderingar av mänskliga preferenser på Alibaba AI Arena.
Parametrar
6B
Kompakt men kraftfull
Steg (Turbo)
8
Snabb generering
VRAM krävs
<16GB
Konsumenthårdvara
Vad skapare säger om Z-Image
Erfarenheter från designers, utvecklare och innehållsskapare som använder våra verktyg.
David
Grafisk designer
Den fotorealistiska kvaliteten konkurrerar med dyra kommersiella verktyg. Jag integrerade det i min ComfyUI-pipeline på några minuter.
Rachel
Innehållsskapare
Tvåspråkig textrendering är en spelväxlare. Kinesiska tecken kommer ut skarpa utan efterbehandling.
Marcus
Utvecklare
Laddade ner GGUF-versionen från Huggingface och fick den igång lokalt samma eftermiddag. Mycket enkelt.
Sofia
Marknadschef
Edit-varianten följer komplexa instruktioner exakt. Vi använder den för snabba produktfotojusteringar.
James
E-handel
Scenkompositonsförståelsen är utmärkt. Produktbakgrunder ser professionellt fotograferade ut.
Anna
Konstnär
Kulturell noggrannhet imponerade på mig. Den genererade specifika landmärken och traditionella element utan hallucinationer.
Vanliga frågor om Z-Image
Allt du behöver veta om Z-Image, ComfyUI-integration och nedladdning från Huggingface.
Vad är Z-Image egentligen?
Z-Image är en effektiv grundmodell med 6 miljarder parametrar för att generera bilder. Byggd på en Single-Stream Diffusion Transformer-arkitektur, levererar den fotorealistisk kvalitet och tvåspråkig textåtergivning jämförbar med ledande kommersiella lösningar – utan att kräva enorma beräkningsresurser.
Hur fungerar enkelströms diffusionsarkitekturen?
Denna arkitektur förenar bearbetningen av textinbäddningar, villkorliga inmatningar och brusiga latenter till en enda sekvens som matas in i transformatorns ryggrad. Detta strömlinjeformade tillvägagångssätt förbättrar effektiviteten samtidigt som den bibehåller hög utskriftskvalitet, vilket gör att modellen kan köras på hårdvara av konsumentklass.
Vad är Z-Image-Turbo?
Z-Image-Turbo är en destillerad variant optimerad för hastighet. Den uppnår fotorealistisk generering med exakt tvåspråkig textåtergivning i bara 8 slutledningssteg, vilket ger resultat som är jämförbara med eller överträffar konkurrenter som kräver många fler steg.
Vad är Z-Image-Edit?
Z-Image-Edit är en variant av fortsättningsutbildning specialiserad för att modifiera befintliga bilder. Den utmärker sig på att följa komplexa instruktioner för uppgifter som sträcker sig från exakta lokala justeringar till globala stiltransformationer samtidigt som redigeringskonsistensen bibehålls.
Kan jag använda detta med ComfyUI?
Ja. Modellen integreras naturligt med ComfyUI genom anpassade noder. Du kan bygga komplexa arbetsflöden som kombinerar generering, redigering och efterbehandling allt inom ComfyUI-gränssnittet. Community-skapade arbetsflödesmallar finns tillgängliga för att hjälpa dig komma igång snabbt.
Var kan jag ladda ner vikterna?
Modellvikter finns på både Huggingface och ModelScope. Du kan ladda ner basmodellen, Turbo-varianten eller Edit-varianten beroende på ditt användningsfall. GGUF och FP8 kvantiserade versioner tillhandahålls också för effektiv lokal distribution.
Vilken hårdvara behöver jag för att köra den lokalt?
Modellen körs smidigt på grafikkort för konsumenter med mindre än 16 GB VRAM. Detta gör avancerad genereringsteknik tillgänglig utan att kräva dyr professionell hårdvara. De kvantiserade GGUF- och FP8-versionerna minskar minneskraven ytterligare.
Stöder den kinesisk text i genererade bilder?
Ja. Modellen har utmärkta tvåspråkiga renderingsmöjligheter för både kinesisk och engelsk text. Den kan exakt placera text i bilder samtidigt som estetisk komposition och läsbarhet bibehålls, även vid mindre teckenstorlekar.
Hur jämförs prestandan med andra open source-modeller?
Enligt Elo-baserad Human Preference Evaluation på Alibaba AI Arena visar denna modell mycket konkurrenskraftiga prestanda mot ledande alternativ och uppnår toppmoderna resultat bland open source-alternativ i sin parameterklass.
Vad är promptförbättraren?
Promptförbättraren (PE) använder en strukturerad resonemangskedja för att injicera logik och sunt förnuft i genereringsprocessen. Detta möjliggör hantering av komplexa uppgifter som kycklings-och-kanin-problemet eller visualisering av klassisk poesi med logisk koherens.
Är modellen verkligen öppen källkod?
Ja. Koden, vikterna och en onlinedemo är offentligt tillgängliga. Målet är att främja utvecklingen av tillgängliga, lågkostnads, högpresterande generativa modeller som gynnar hela forskar- och utvecklargemenskapen.
Kan den hantera komplexa flerdelsinstruktioner?
Edit-varianten utmärker sig särskilt här. Den kan köra sammansatta instruktioner som att samtidigt modifiera en karaktärs uttryck och posering samtidigt som du lägger till specifik text, vilket bibehåller konsistens över alla ändringar.
Hur implementeras kulturell förståelse?
Modellen har omfattande kunskap om världens landmärken, historiska figurer, kulturella koncept och specifika verkliga objekt. Detta möjliggör exakt generering av olika ämnen utan hallucinationer eller kulturella felaktigheter.
Vad gör textrenderingen speciell?
Utöver tvåspråkigt stöd visar modellen starka typografiska färdigheter för affischdesign och komplexa kompositioner. Den hanterar utmanande scenarier som små teckenstorlekar eller intrikata layouter samtidigt som textuell precision och visuell tilltalande bibehålls.
Hur integrerar jag det i min befintliga pipeline?
För ComfyUI-användare, ladda helt enkelt ner de anpassade noderna och ladda vikterna. För programmatisk åtkomst följer modellen standard diffusionsmodell-API:er. Dokumentationen inkluderar exempelkod för Python-integration, API-slutpunkter och arbetsflödesmallar.
Vad gäller FP8- och GGUF-versionerna?
Dessa är kvantiserade versioner optimerade för effektiv distribution. FP8 bibehåller hög kvalitet med minskad precision, medan GGUF ger maximal kompatibilitet för lokal inferens. Båda minskar VRAM-kraven under basmodellen.
Kan jag använda den för kommersiella projekt?
Modellen släpps som öppen källkod med en tillåtande licens. Kontrollera de specifika licensdetaljerna på arkivsidan för riktlinjer för kommersiell användning. De flesta standardkommersiella applikationer är tillåtna.
Hur jämförs den med Stable Diffusion?
Även om båda är diffusionsbaserade använder denna modell en distinkt enkelströmsarkitektur som förenar bearbetningen. Den utmärker sig särskilt i tvåspråkig textrendering och instruktionsföljning, områden där standard Stable Diffusion-modeller ofta kämpar.
Vilken upplösning stöder den?
Basmodellen stöder standardupplösningar optimerade för kvalitets- och hastighetsbalans. Högre upplösningar är möjliga genom ComfyUI-arbetsflödet med lämpliga uppskalningsnoder. Kontrollera dokumentationen för rekommenderade upplösningsinställningar.
Finns det ett API tillgängligt?
Ja. Både en webbdemo och programmatisk API-åtkomst tillhandahålls. Du kan integrera genereringsmöjligheter direkt i dina applikationer utan att hantera lokal infrastruktur om det föredras.
Hur ofta uppdateras modellen?
Utvecklingsteamet underhåller och förbättrar aktivt modellen. Uppdateringar inkluderar prestandaoptimeringar, utökade möjligheter och community-efterfrågade funktioner. Följ arkivet för tillkännagivanden.
Kan den generera ansikten exakt?
Modellen producerar mycket realistiska ansiktsdrag med fin kontroll över uttryck och detaljer. Kombinerat med exakta textöverlagringsmöjligheter är den särskilt lämpad för porträttbaserat innehåll och marknadsföringsmaterial.
Vad gäller stilöverföring och konstnärliga effekter?
Edit-varianten hanterar stiltransformationer samtidigt som ämnesidentiteten bevaras. Du kan använda konstnärliga effekter, ändra bakgrunder eller ändra estetik samtidigt som du behåller konsistensen i de visuella kärnelementen.
Hur fungerar LoRA-anpassningar med denna modell?
Anpassade LoRA-vikter kan tränas och tillämpas för att specialisera modellen för specifika stilar eller ämnen. Arkitekturen stöder standard LoRA-integrationsmetoder som är bekanta för användare av andra diffusionsmodeller.
Vad gör den effektiv jämfört med större modeller?
Systematisk optimering på arkitekturnivå gör att 6B parametrar kan matcha output från modeller 10 gånger större. Denna effektivitet översätts till snabbare inferens, lägre hårdvarukrav och minskade driftskostnader.
Finns community-support tillgängligt?
Ja. Aktiva gemenskaper finns på Discord, GitHub och forum där användare delar arbetsflöden, felsöker problem och visar upp skapelser. Utvecklingsteamet engagerar sig regelbundet med community-feedback.
Hur rapporterar jag buggar eller begär funktioner?
GitHub-arkivet accepterar ärenden för buggrapporter och funktionsförfrågningar. Community-deltagande hjälper till att prioritera förbättringar och säkerställer att modellen utvecklas för att möta användarnas behov.
Kan nybörjare använda detta utan teknisk kunskap?
Webbdemon ger ett gränssnitt utan kod för omedelbar användning. För lokal distribution erbjuder ComfyUI visuell arbetsflödesbyggnad utan kodning. Tekniska användare kan komma åt hela API:et för programmatisk kontroll.
Vad skiljer detta från Qwen-baserade bildmodeller?
Medan Qwen fokuserar på förståelse av vision-språk, är denna modell specialiserad på generering med unika styrkor i tvåspråkig textåtergivning och instruktionsföljande redigering. Båda kan komplettera varandra i omfattande AI-pipelines.
Stöds batchbearbetning?
Ja. Både API:et och ComfyUI-arbetsflöden stöder batchgenerering för effektiv bearbetning av flera prompter. Detta är användbart för produktionsmiljöer som kräver hög genomströmning.
Börja skapa med Z-Image
Upplev effektiv generering med denna grundmodell med öppen källkod. Gratis att använda.